Range Update an Array in Constant Time
Given an array arr of size $n$ with all elements initialized to $0$. Implement void add(int[] arr, int l, int r, int num) and void print(int[] arr) which meet the following requirements:
add function: add num to each index between l to index r inclusivle. For example:
1 | |
print function: print the final array:
1 | |
For add function, we can simply using a for loop to add the element:
1 | |
But the above function takes $O(n)$ time complexity. In order to make it faster in $O(1)$ time, we do this:
1 | |
Visualize:
1 | |
1 | |
The first element is not changed, other elements will equal to the sum of its previous element.
Visualize:
1 | |
Find Merge Point of Two Lists
Given two linked lists, find the merge node of these two linked lists.
1 | |
First, we can compare LinkedList 1 and LinkedList 2’s last node, if the last node is different, then these two linkedlists do not have merge node. If the last node is the same, then we compare their sizes, and advance the longer linkedlist by the difference of their sizes. For example, on the above diagram, LinkedList 1 is the longer linkedlist, and we move the current node from a to b. Then, both linked list start at the same time to advance the current node until both linkedlist have the same node, and that node will become the merge node. The code below implements this algorithm:
1 | |
Another approach is even simpler. Same as the last approach, first check their last node, if they do not have the same last node, then there is no merge node. Else, iterate both linkedlist at the same time, if one linkedlist reach the end, start from another linkedlist, until they have the same node. Then that node is the merge node.
1 | |
Explanation:
If the first linkedlist has size $x$, merge point is at the $i$ node. The second linkedlist has size $y$, merge point is at the $j$ node.
The first linkedlist needs to travel $i$ steps to reach the merge node, and $x-i$ steps to reach the end of the first linkedlist. Then, it takes $j$ steps on the second linkedlist to reach the merge node again. Similarly, the second linkedlist needs to travel $j$ steps to reach the merge node, and $y-j$ steps to reach the end. Then, it takes $i$ steps on the first linkedlist to reach the merge node.
FirstLinkedList reaches the merge node the second times: $i + (x-i) + j$. SecondLinkedList reaches the merge node the second times: $j + (y-j) + i$.
Since the size from the beginning of merge node to the end is the same for both linkedlist, which means $x-i = y-j$. Therefore, both linkedlists will travel to the merge node at the same number of steps.
Implement Regular Expression Matching
Given a string and a pattern with support for . and *, return true if the string matches the pattern, otherwise return false. For example:
1 | |
It is easy to think about if the pattern only has one character, if that character is not a . and it is not equals to the first character of the string, then we return false.
If the pattern has length at least two, then we consider the second character of pattern, if it is a * or it is not a *.
If the second character is not a *, then we simply check if the first characters are matching, if the first character is not matches, we simply return false, it the first characters are match, then recursivly call the isMatch for both strings starting from their second characters.
If the second character is a *, then we need to consider case 1: * is functions for zero of the first character, and case 2 is * is functions for one or more of the first character.
Case 1: we can simply call isMatch for the original string and the pattern starts from the third character.
Case 2: while the first character of string matches the first character of pattern, we iterates the next character of string and compare it with the first character of pattern until they do not match, we call isMatch for the character of string that does not match the first character with the pattern starts from the third character.
1 | |
But this approach does not work, because if the first character of the pattern is ., then it always matches the first character of the string and the iterative one. Consider this isMatch("aaab", ".*b"). So, after we check the i character matches the first character of the pattern, we need to check isMatch(s.substring(i + 1), p.substring(2)), if it mathes, we can simply return true as the result. If they do not match, it’s fine, we still increase i. If i is greater than s.length(), then we return false.
1 | |
The final code is below:
1 | |
Maintain Decreasing Order of Numbers in an Array
Given an array of numbers, each time if the number with index $i$ is greater than the number of index $i-1$, then the number with index $i$ will be removed. The question is after how many times, no element will be removed. For example,
Given an array p = [6, 5, 8, 7, 4, 7, 3, 1, 1, 10].
On day 1, p = [6, 5, 7, 4, 3, 1, 1]
On day 2, p = [6, 5, 4, 3, 1, 1]
So after 2 days, no element will be removed.
First, we can simply come up with the idea that loop through the array and save all indexes that have the value greater than its previous element to a list. Then, we remove these elements according to the saved index list. Repeat this process until all elements maintain the decreasing order.
In this approach, we take $O(N)$ to loop through the array, and take $O(N)$ to remove each element. Therefore, it takes $O(n^2)$ time complexity.
The remove instruction takes a lot of time, how can we make it faster?
The answer is it can be done with linkedlist of linkedlst, for example,
Day 0, [6 5 8 7 4 7 3 1 1 10], we can write it as 6->5, 8->7->4, 7->3->-1->1, 10, each sublist is the longest decreasing order sublist it can be.
Day 1, we remove the first element of the sublist except the first sublist:
6->5, 7->4, 3->1->1
Now, we check to see if sublist can merge, here the second sublist’s last element is greater than the first element of the thrid sublist, so they can be merged:
6->5, 7->4->3->1->1
Day 2, we remove the first element of the sublist except the first sublist:
6->5, 4->3->1->1
Now, we see that they can be merged to a single sublist and we are done:
6->5->4->3->1->1
In this approach, the remove instruction takes $O(1)$ time complexity, and therefore it’s faster.
Final code is below:
1 | |
QuickSort QuickSelect TopK
QuickSort algorithm
1 | |
Kth Largest Element in an Array
Find the kth largest element in an unsorted array. Note that it is the kth largest element in the sorted order, not the kth distinct element.
1 | |
MergeSort
MergeSort Algorithm
1 | |
Reverse Pairs
Given an array nums, we call (i, j) an important reverse pair if i < j and nums[i] > 2*nums[j].
You need to return the number of important reverse pairs in the given array.
Example1:
1 | |
Example2:
1 | |
1 | |
Topological Sort
Topological sorting for Directed Acyclic Graph (DAG) is a linear ordering of vertices such that for every directed edge u->v, vertex u comes before v in the ordering. Topological Sorting for a graph is not possible if the graph is not a DAG.
For example, a topological sorting of the following graph is “5 4 2 3 1 0”. There can be more than one topological sorting for a graph. For example, another topological sorting of the following graph is “4 5 2 0 3 1”. The first vertex in topological sorting is always a vertex with in-degree as 0 (a vertex with no incoming edges). One example for Topological Sort is build dependency problem. If dependencyA depends on dependencyB and dependencyC, then dependencyA can be resolved anytime after dependencyB and dependencyC are resolved.
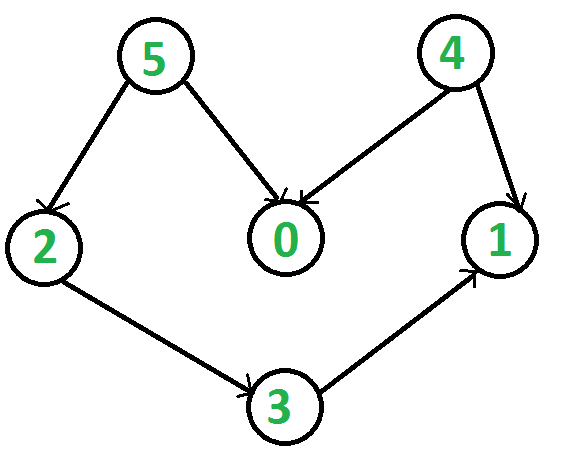
Topological Sorting vs Depth First Traversal (DFS):
For example, in the given graph, the vertex ‘5’ should be printed before vertex ‘0’, but unlike DFS, in topological sort, the vertex ‘4’ should also be printed before vertex ‘0’. So Topological sorting is different from DFS. For example, a DFS of the shown graph is “5 2 3 1 0 4”, but it is not a topological sorting.
TopologicalSort using Queue
1 | |
TopologicalSort using Stack
1 | |
Source: