Starting August, LeetCode will also include premium questions in August LeetCoding Challenge.
Week 1: August 1st - August 7th
Logger Rate Limiter
Design a logger system that receive stream of messages along with its timestamps, each message should be printed if and only if it is not printed in the last 10 seconds.
Given a message and a timestamp (in seconds granularity), return true if the message should be printed in the given timestamp, otherwise returns false.
It is possible that several messages arrive roughly at the same time.
Example:
1 | |
Explanation
-
If we use brute force solution, we can create a hashmap, key is the message string, value is the timestamp. For each
shouldPrintMessagemethod call, we check if themessageargument is in the hashmap or not. If not, then that means this message didn’t appear before, so we return true and put this message and timestamp to the hashmap. Else, we compare thehashmap.get(message)withtimestampto see if thistimestampis in the range or not. This will have space complexity $O(n)$. -
We can reduce space complexity to $O(1)$ by creating two hashmaps. The first hashmap is used to store the timestamp within last 0 to 10 seconds, the second hashmap is the OLD last 0 to 10 seconds hashmap. We also need an extra variable
twhich represents the initial time that starts checking the last 10 seconds hashmap. -
When the message comes in, we check if this message is in the previous 0 to 10 seoncd hashmap, if yes, then we return false.
-
Next, we also need to check if this message is in the OLD hashmap, if yes, then we compare
old[message] + 10andtimestamp, iftimestampis smaller, then return false. The reason is if we start checking the last 10 seconds fromt = 11, in other words, now the last 10 seconds is from11 - 21second, there was a message at 9 second in the OLD hashmap, now the same message comes in at 15 second, we still need to return false because 9 + 10 > 15. -
Next, the current message is not in both hashmap, then we add it to the
pre0To10hashmap. -
When do we update the OLD hashmap? That’s why we need to variable
t. If the incoming messagetimestamp >= t + 10, then we update the old hashmap be the currentpre0To10hashmap, and udpatetbe the current incomingtimestamp.
Solution
1 | |
Detect Capital
Given a word, you need to judge whether the usage of capitals in it is right or not.
We define the usage of capitals in a word to be right when one of the following cases holds:
-
All letters in this word are capitals, like “USA”.
-
All letters in this word are not capitals, like “leetcode”.
-
Only the first letter in this word is capital, like “Google”.
Otherwise, we define that this word doesn’t use capitals in a right way.
Example 1:
1 | |
Example 2:
1 | |
Note: The input will be a non-empty word consisting of uppercase and lowercase latin letters.
Explanation
-
If we know the first two characters, then we can determine the result base on the rest of characters.
-
If both the first two characters are upper case, then the rest characters should all be upper case. For example,
AB(XYZ),XYZmust all be upper case in order to be True. -
Else both the first two characters are not upper case, then from the second character and beyond, the rest characters must all be lower case. For example,
A(bxyz),a(Bxyz),a(bxyz).
Solution
1 | |
Design HashSet
Design a HashSet without using any built-in hash table libraries.
To be specific, your design should include these functions:
-
add(value): Insert a value into the HashSet. -
contains(value): Return whether the value exists in the HashSet or not. -
remove(value): Remove a value in the HashSet. If the value does not exist in the HashSet, do nothing.
Example:
1 | |
Note:
-
All values will be in the range of
[0, 1000000]. -
The number of operations will be in the range of
[1, 10000]. -
Please do not use the built-in HashSet library.
Explanation
-
We can solve this problem and collision using seperate chaining. First, we create an array of list
List<Integer>[] buckets, in other word, adjacency list, and also initialize the size of this array is 15000 which is 150% of the total keys since the range of the number of operation is[1, 10000]so that we can avoid most the collision. -
We also need to define our hash function, which can simpliy be
key % numBuckets. -
In the
addmethod, first calculate the hash indexidx, so that we know this inputkeyis belonged to which bucket, then put the inputkeyinto the corresponding bucketbucket[idx], but before we put, we need to make sure the listbuckets[idx]doesn’t have the input key. -
In the
removemethod, first calculate the hash indexidx, then make sure the listbucketx[idx]has thekey, then we remove thekey. -
In the
containsmethod, first calculate the hash indexidx, then check if the corresponding bucketbucket[idx]doesn’t have thekey.
Solution
1 | |
Valid Palindrome
Given a string, determine if it is a palindrome, considering only alphanumeric characters and ignoring cases.
Note: For the purpose of this problem, we define empty string as valid palindrome.
Example 1:
1 | |
Example 2:
1 | |
Constraints:
sconsists only of printable ASCII characters.
Explanation
- We can use a left and right poitner pointing to the beginning and the end of the string respectivly, and compare their character. If the character is pointing at is not a letter or digit, then we skip it; else if the character is not match, then we return false; else if they are matched, then we move left pointer to the right, right pointer to the left. Repeat it until left pointer is equal or greater than right pointer.
Solution
1 | |
Power of Four
Given an integer (signed 32 bits), write a function to check whether it is a power of 4.
Example 1:
1 | |
Example 2:
1 | |
Follow up: Could you solve it without loops/recursion?
Explanation
-
First, zero is not the power of any number. We can write out some numbers that are power of 4 in their binary representation.
1
2
3
41 1 4 100 16 10000 64 1000000 -
We notice that they all starts from 1 and only have one 1 in the most significant bit, and the next number have two more zeros at the end. We can use the technique of finding powerOf2 because all numbers that are powerOf2 only have the most significant bit is 1. If
(num & (num-1)) == 0, thennumis powerOf2. -
If we always shift two bits to the right, then if
numis powerOf4, it must sometimes equals to 1. -
Any negative numbers will return false.
Solution
1 | |
Add and Search Word - Data structure design
Design a data structure that supports the following two operations:
1 | |
search(word) can search a literal word or a regular expression string containing only letters a-z or .. A . means it can represent any one letter.
Example:
1 | |
Note:
You may assume that all words are consist of lowercase letters a-z.
Hint 1:
You should be familiar with how a Trie works. If not, please work on this problem: Implement Trie (Prefix Tree) first.
Explanation
-
Similar to 208. Implement Trie (Prefix Tree), we need two properties:
WordDictionary[26] childrenandboolean isEndOfWord. -
For the
addWordmethod, it’s the same as how the Trie add word. -
For the
searchmethod, if the word doesn’t have any.character, then it’s the same as how the Trie search word. If word’s current character is., in other wrod,word[i] = '.', then we need to check all the children under the current Trie pointer, and recursively call each child’ssearchmethod with the updated wordword[i+1:].
Solution
1 | |
Find All Duplicates in an Array
Given an array of integers, 1 ≤ a[i] ≤ n (n = size of array), some elements appear twice and others appear once.
Find all the elements that appear twice in this array.
Could you do it without extra space and in O(n) runtime?
Example:
1 | |
Explanation
- Since in the array, all elements are positive and their value are no more than
n. We loop the array, for each iteration, we think the current value as an index which isidx = curVal-1. Then we make that index’s value be negative, in other words,arr[idx] *= -1. So, when we iterate the array, before we makearr[idx]be negative, if it’s already negative, that means there are same value asidxbefore, so we add the before’s value which iscurValto the result list.
Solution
1 | |
Vertical Order Traversal of a Binary Tree
Given a binary tree, return the vertical order traversal of its nodes values.
For each node at position (X, Y), its left and right children respectively will be at positions (X-1, Y-1) and (X+1, Y-1).
Running a vertical line from X = -infinity to X = +infinity, whenever the vertical line touches some nodes, we report the values of the nodes in order from top to bottom (decreasing Y coordinates).
If two nodes have the same position, then the value of the node that is reported first is the value that is smaller.
Return an list of non-empty reports in order of X coordinate. Every report will have a list of values of nodes.
Example 1:
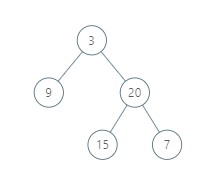
1 | |
Example 2:
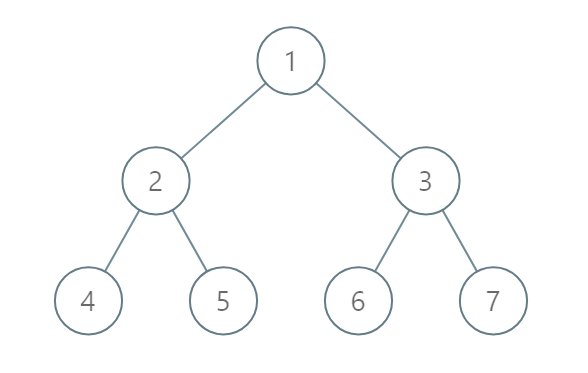
1 | |
Note:
-
The tree will have between 1 and
1000nodes. -
Each node’s value will be between
0and1000.
Explanation
-
We can create a hashmap, key will be the column number, value will be a list of
pair< row number, node value>. This list will later be sorted by smaller row number to large row number, if same row number, then sort by small node value to large node value. We can use pre-order traversal to generate this map. When building this map, we also keep track of the minimum column number, and maximum column number. -
Next, loop from the minimum column to maximum column. Each iteration, we can get a list of
pair<row number, node value>and sort this list. Now, we can loop through this list’s node value and put into a sub list, then put this sublist to the result list.
Solution
1 | |
Week 2: August 8th - August 14th
Closest Binary Search Tree Value
Given a non-empty binary search tree and a target value, find the value in the BST that is closest to the target.
Note:
-
Given target value is a floating point.
-
You are guaranteed to have only one unique value in the BST that is closest to the target.
Example:
1 | |
Explanation
-
Since this is the binary tree, we have 3 cases.
-
First case is if
targetis less thanroot.valandroot.leftis not null, then we recursively call the main function withroot.leftandtargetand it returns the closest valuelfrom the treeroot.left. Then we compareabs(l - target)andabs(root.val - target)and return the smalleset difference’s tree value. -
Second case is if
targetis greater thanroot.valandroot.rightis not null. This is similar to the above case. -
Third case is
targetis equal toroot.val, ortargetis less thanroot.valbutroot.leftis null, ortargetis greater thanroot.valbutroot.rightis null, then we just returnroot.val.
Solution
1 | |
Path Sum III
You are given a binary tree in which each node contains an integer value.
Find the number of paths that sum to a given value.
The path does not need to start or end at the root or a leaf, but it must go downwards (traveling only from parent nodes to child nodes).
The tree has no more than 1,000 nodes and the values are in the range -1,000,000 to 1,000,000.
Example:
1 | |
Explanation 1
- We have two options. One is include the root node’s value as the sum and call a helper function with root node as a parameter, the other is don’t include the root node’s value and call the main function with the left child and right child respectively.
Solution 1
1 | |
Explanation 2
-
Similar to 560. Subarray Sum Equals K, we can create a hashmap to store the accumulate sum as the key, and the count of this sum as the value. Initially, the hashmap will have key as 0, value as 1. We will update the result as
res += hm[curSum - targetSum]. For example, the tree is like below, and the target sum is 3.1
2
3
4
51 / 2 / 1 -
When we on the first node 1, we have
curSumis 1, we increaseresby 0 (hm[1 - 3] = 0), then we update the hashmap and havehm[1] = 1. Next, we are on the node 2, we havecurSumis 3, we increaseresby 1 (hm[3-3]=1), then we update the hashmap and havehm[3] = 1. Next, we are on the second node 1, we havecurSum = 4, we increaseresby 1 (hm[4-3]=1) and nowres = 2, then we update the hashmap and havehm[4] = 1. -
At the end of each recursion call, we need to backtrack the hashmap key and value since we don’t want to carry these keys and values to the right child.
Solution 2
1 | |
Rotting Oranges
In a given grid, each cell can have one of three values:
-
the value
0representing an empty cell; -
the value
1representing a fresh orange; -
the value
2representing a rotten orange.
Every minute, any fresh orange that is adjacent (4-directionally) to a rotten orange becomes rotten.
Return the minimum number of minutes that must elapse until no cell has a fresh orange. If this is impossible, return -1 instead.
Example 1:
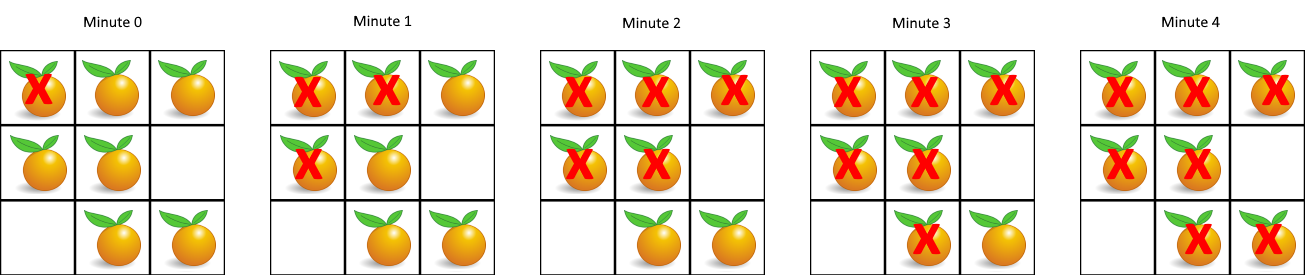
1 | |
Example 2:
1 | |
Example 3:
1 | |
Note:
-
1 <= grid.length <= 10 -
1 <= grid[0].length <= 10 -
grid[i][j]is only0,1, or2.
Solution
1 | |
Excel Sheet Column Number
Given a column title as appear in an Excel sheet, return its corresponding column number.
For example:
1 | |
Example 1:
1 | |
Example 2:
1 | |
Example 3:
1 | |
Constraints:
-
1 <= s.length <= 7 -
sconsists only of uppercase English letters. -
sis between “A” and “FXSHRXW”.
Explanation
-
This is a problem that asks us to convert a twenty-six hex to a decimal number.
-
We can start from the most right, ‘A’ is 1, so we can do ‘A’ - ‘A’ + 1 = 1, then multiple by 26 to the power of 0; ‘B’ is 2, we can do ‘B’ - ‘A’ + 1 = 2, multiple by 26 to the power of 0. Similarlly, the second right number multiple by 26’s to the power of 1.
Solution
1 | |
H-Index
Given an array of citations (each citation is a non-negative integer) of a researcher, write a function to compute the researcher’s h-index.
According to the definition of h-index on Wikipedia: “A scientist has index h if h of his/her N papers have at least h citations each, and the other N − h papers have no more than h citations each.”
Example
1 | |
Note: If there are several possible values for h, the maximum one is taken as the h-index.
Hint 1:
An easy approach is to sort the array first.
Hint 2:
What are the possible values of h-index?
Hint 3:
A faster approach is to use extra space.
Explanation
-
First, sort the input array.
-
Start from the last index to index 0, initialize
count = 1. Ifarr[i] >= count, then updateres = count. Each iteration increasecountby 1. Repeat the above step, ifarr[i] < count, we can break out the loop and return theres.
Solution
1 | |
Pascal’s Triangle II
Given a non-negative index k where k ≤ 33, return the kth index row of the Pascal’s triangle.
Note that the row index starts from 0.
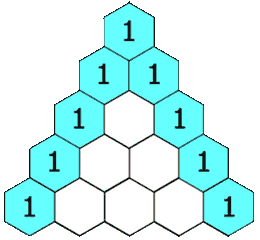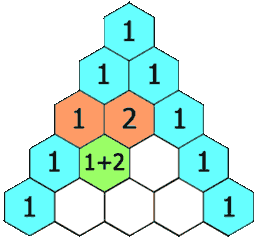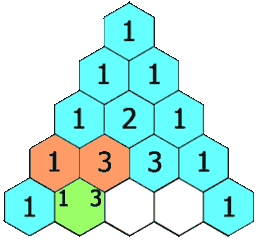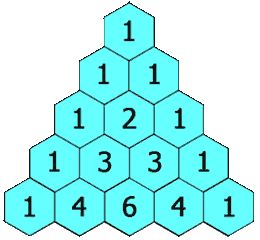
In Pascal’s triangle, each number is the sum of the two numbers directly above it.
Example:
1 | |
Follow up:
Could you optimize your algorithm to use only O(k) extra space?
Explanation
-
If
rowIndex = n, then the result will have lengthn + 1. Initially, we create the result list that has lengthn + 1and set all elements to be 1. -
If
curRowIndex = 2, then initially we haveres = [1, 1, 1]. Then we start updating index fromcurRowIndex - 1which is 1 to beres[1] = res[1] + res[0] = 2. Now, we getres = [1, 2, 1]. -
If
rowIndex = 3and we already solverowIndex = 2using the above method, and we haveres = [1, 2, 1, 1]. Foristarting fromcurRowInex - 1down to 1, we updateres[i] = res[i] + res[i-1], then we have wheni = 2,res = [1, 2, 3, 1]; wheni = 1,res = [1, 3, 3, 1].
Solution
1 | |
Iterator for Combination
Design an Iterator class, which has:
-
A constructor that takes a string
charactersof sorted distinct lowercase English letters and a numbercombinationLengthas arguments. -
A function next() that returns the next combination of length
combinationLengthin lexicographical order. -
A function hasNext() that returns
Trueif and only if there exists a next combination.
Example:
1 | |
Constraints:
-
1 <= combinationLength <= characters.length <= 15 -
There will be at most
10^4function calls per test. -
It’s guaranteed that all calls of the function
nextare valid.
Hint 1:
Generate all combinations as a preprocessing.
Hint 2:
Use bit masking to generate all the combinations.
Explanation:
-
Similar to 77. Combinations, first in the constructor method, we need to create a list of the combinations in the queue.
-
In the
nextmethod, we poll the first string from the queue. -
In the
hasNextmethod, we check if the queue is empty or not.
Solution
1 | |
Longest Palindrome
Given a string which consists of lowercase or uppercase letters, find the length of the longest palindromes that can be built with those letters.
This is case sensitive, for example "Aa" is not considered a palindrome here.
Note:
Assume the length of given string will not exceed 1,010.
Example:
1 | |
Explanation
-
Palindrome normally has even number of characters, like
cbaabc. Or has one odd number of character in the middle, likecbaxabc. -
We can use a hashmap to get all characters’ frequency. Then, we loop through all hashmap’s frequency. If the current frequency is even, we just add the frequency into result. Else if the current frequency is odd, then we add its frequency and subtract 1. (if there are 3
as, then we add 3-1=2as into the result). Also, we marktruethat there’s at least one odd character. -
At the end, if no
oddnumber of character, then we returnres. Else if there’s at least 1 odd number of character, we returnres + 1because one character can be added into the middle.
Solution
1 | |
Week 3: August 15th - August 21st
Find Permutation
By now, you are given a secret signature consisting of character ‘D’ and ‘I’. ‘D’ represents a decreasing relationship between two numbers, ‘I’ represents an increasing relationship between two numbers. And our secret signature was constructed by a special integer array, which contains uniquely all the different number from 1 to n (n is the length of the secret signature plus 1). For example, the secret signature “DI” can be constructed by array [2,1,3] or [3,1,2], but won’t be constructed by array [3,2,4] or [2,1,3,4], which are both illegal constructing special string that can’t represent the “DI” secret signature.
On the other hand, now your job is to find the lexicographically smallest permutation of [1, 2, … n] could refer to the given secret signature in the input.
Example 1:
1 | |
Example 2:
1 | |
Note:
-
The input string will only contain the character ‘D’ and ‘I’.
-
The length of input string is a positive integer and will not exceed 10,000
Explanation
-
This problem can be solved by greedy or brute force.
-
For example, if the input string is “DDIIDI”, then the result changes from “1 2 3 4 5 6 7” to “3 2 1 4 6 5 7”.
D D I I D I
1 2 3 4 5 6 7
3 2 1 4 6 5 7
-
From the above example, we notice that we only need to reverse D’s surrounding numbers. We record D’s starting index
jand the countcntof continuous D, then reverseres[j, j+cnt]inclusive.
Solution
1 | |
Non-overlapping Intervals
Given a collection of intervals, find the minimum number of intervals you need to remove to make the rest of the intervals non-overlapping.
Example 1:
1 | |
Example 2:
1 | |
Example 3:
1 | |
Note:
-
You may assume the interval’s end point is always bigger than its start point.
-
Intervals like [1,2] and [2,3] have borders “touching” but they don’t overlap each other.
Explanation
-
First, we need to sort the
intervals[][]by theirstart. When we have less than two intervals, we can return 0 as the result. -
Next, we need to find out which intervals are overlap. The way to find overlap is if the current interval’s start is less than the last included interval’s end. So if we find overlap, we need to remove 1 of the interval.
-
We should remove the interval that has the bigger end. Here, we are not actually removing it. We can use a variable
lastto mark which interval is the last included interval. So we start from index 1, and compareinterval[last]withinterval[i]. -
If the current interval is not overlapped with the last included interval, we mark the current interval as the new last included interval.
Solution
1 | |
Best Time to Buy and Sell Stock III
Say you have an array for which the ith element is the price of a given stock on day i.
Design an algorithm to find the maximum profit. You may complete at most two transactions.
Note: You may not engage in multiple transactions at the same time (i.e., you must sell the stock before you buy again).
Example 1:
1 | |
Example 2:
1 | |
Example 3:
1 | |
Explanation
-
Note that the maximum transaction is 2, and we can sell and buy on the same day. We can divide this array into two parts:
prices[0:n-1] => prices[0:i] + prices[i:n-1], so we need to find the maximum of profit on or before dayi, and the maximum profit on or after dayi, then the result will be the sum of the two. -
We can solve this problem by calculating every indexes
i’smostLeftProfitandmostRightProfit, then the result will be the maximum of the sum of these two. -
First, we use an array to store all indexes
mostLeftProfitby iterating from beginning to the end. Then, we iterate from the end back to the beginning to calculate themostRightProfitand compare each index’s mostLeftProfit and its mostRightProfit to get the final maximum result.
Solution
1 | |
Distribute Candies to People
We distribute some number of candies, to a row of n = num_people people in the following way:
We then give 1 candy to the first person, 2 candies to the second person, and so on until we give n candies to the last person.
Then, we go back to the start of the row, giving n + 1 candies to the first person, n + 2 candies to the second person, and so on until we give 2 * n candies to the last person.
This process repeats (with us giving one more candy each time, and moving to the start of the row after we reach the end) until we run out of candies. The last person will receive all of our remaining candies (not necessarily one more than the previous gift).
Return an array (of length num_people and sum candies) that represents the final distribution of candies.
Example 1:
1 | |
Example 2:
1 | |
Constraints:
-
1 <= candies <= 10^9
-
1 <= num_people <= 1000
Hint 1:
Give candy to everyone each “turn” first [until you can’t], then give candy to one person per turn.
Explanation
-
We can solve this problem using brute force.
-
While
candiesgreater than 0, we start to givecurcandies. Each iteration, we increment thecur, distributecurtores[idx % num_people]. Also we need to updatecandies -= cur. Note,candies < cur, then we updatecur = candiesand assign it instead.
Solution
1 | |
Numbers With Same Consecutive Differences
Return all non-negative integers of length N such that the absolute difference between every two consecutive digits is K.
Note that every number in the answer must not have leading zeros except for the number 0 itself. For example, 01 has one leading zero and is invalid, but 0 is valid.
You may return the answer in any order.
Example 1:
1 | |
Example 2:
1 | |
Note:
-
1 <= N <= 9 -
0 <= K <= 9
Explanation
-
We can solve this problem using DFS.
-
For example, when
N = 3, K= 7, we have:1
2
3
4
5
6
7
8N = 3, K = 7 1 2 3 4 7 8 / \ / \ / \ / \ / \ / \ - 8 - 9 - - - - 0 - 1 - / \ / \ / \ / \ 1 - 2 - - 7 - 8 -
In the main function, we loop
ifrom 1 to 9 inclusive, each iteration, we recursively call the helper function with the current numberi,N-1, andresas parameters. -
Inside the helper function, the base case is if
Nis 0, that means we finish all the digits, so we return the current number. Else, we can get the last digit of the current number bycur % 10, then we have two cases. First is thelastDgiit - K >= 0, then we recursively call the helper function with the updated current numbercur * 10 + lastDigit - K,N - 1, andres. Second case is checklastDigit + K <= 9, then we recursively call the helper function with the updated current numbercur * 10 + lastDgit + K,N - 1, andres. -
Note, if
Kis 0, the above two cases will have the repeated current number, so we need to check that and run one recursive function whenKis 0. Also whenNis 1, we need to add0to the result list.
Solution
1 | |
Goat Latin
A sentence S is given, composed of words separated by spaces. Each word consists of lowercase and uppercase letters only.
We would like to convert the sentence to “Goat Latin” (a made-up language similar to Pig Latin.)
The rules of Goat Latin are as follows:
- If a word begins with a vowel (a, e, i, o, or u), append
"ma"to the end of the word.
For example, the word ‘apple’ becomes ‘applema’.
- If a word begins with a consonant (i.e. not a vowel), remove the first letter and append it to the end, then add
"ma".
For example, the word "goat" becomes "oatgma".
- Add one letter
'a'to the end of each word per its word index in the sentence, starting with 1.
For example, the first word gets "a" added to the end, the second word gets "aa" added to the end and so on.
Return the final sentence representing the conversion from S to Goat Latin.
Example 1:
1 | |
Example 2:
1 | |
Notes:
-
Scontains only uppercase, lowercase and spaces. Exactly one space between each word. -
1 <= S.length <= 150.
Explanation
-
To determine if the first character is vowel, we can put all vowel into a set, then check if the set has this character or not.
-
For the suffix of
a, we can use a string builder to build the suffix. Each iteration, we appendato the string builder. -
We can split the string by space, then loop through each word. First append
ato the suffix. Then check if the word’s first character is vowel, then we can append the word, the"ma", the suffix and the space. Else if the word’s first character is not vowel, we need to modify the word, append"ma"the suffix and the space. At the end remove the last space and return the result.
Solution
1 | |
Reorder List
Given a singly linked list L: L0→L1→…→Ln-1→Ln, reorder it to: L0→Ln→L1→Ln-1→L2→Ln-2→…
You may not modify the values in the list’s nodes, only nodes itself may be changed.
Example 1:
1 | |
Example 2:
1 | |
Explanation 1
-
Make a
curpointer to the head, while the pointer is not null, pushcurpointer’s node to the stack. -
Note, if there are 4 nodes like
1->2->3->4, then we only need to popn = (stack.size()-1)/2 = (4-1)/2 = 1time. Because we just want to connect1->4, but2->3is already connected. After we finish popingntimes, we set3->null, which isst.peek().next = null. -
Make
curpointer points back to the head. Now the top node of the stack is the next node ofcur. We can pop it and set it tocur.nextand move thecurto the right position and decrease the counter.
Solution 1
1 | |
Explanation 2
-
We don’t need the stack and reduce space complexity to $O(1)$. We notice that in the stack approach, we only care about the second half of the list. For example if the input list is
1 -> 2 -> 3 -> 4 -> 5, then the result is1 -> 5 -> 2 -> 4 -> 3, and we notice that the second half4 -> 5is reversed. So we can reverse the second half of the input list, then connect first half’s node and second half’s node one at a time. For example, we connect1 -> 5, then2 -> 4. -
To reverse the second half of the input list node, we can apply the slow and fast pointer approach to get the middle node or the second half’s first node, then from there, we reverse the node to the end.
-
After we reverse, we have
1 -> 2 -> 3 <- 4 <- 5. Now,headpoints at 1 andprepoints at5. In other words, we can think of two list nodes.n1 = 1 -> 2 -> 3, andn2 = 5 -> 4 -> 3 -> null. -
While
n2.next != null, we connect 1 and 5, then 2 and 4.
Solution 2
1 | |
Sort Array By Parity
Given an array A of non-negative integers, return an array consisting of all the even elements of A, followed by all the odd elements of A.
You may return any answer array that satisfies this condition.
Example 1:
1 | |
Note:
-
1 <= A.length <= 5000 -
0 <= A[i] <= 5000
Explanation
-
We can solve this problem using two pointers approach.
-
Create a pointer
lpoints to the first index of the array, another pointerrpoionts to the last index of the array. Whilel < r, whileA[l]is even number, we increasel; whileA[r]is odd number, we decreaser. NowA[l]is odd number andA[r]is even number, so we swap them. Then increase pointerland decrease pointerr. Repeat whilel < r.
Solution
1 | |
Week 4: August 22nd - August 28th
The Maze
There is a ball in a maze with empty spaces and walls. The ball can go through empty spaces by rolling up, down, left or right, but it won’t stop rolling until hitting a wall. When the ball stops, it could choose the next direction.
Given the ball’s start position, the destination and the maze, determine whether the ball could stop at the destination.
The maze is represented by a binary 2D array. 1 means the wall and 0 means the empty space. You may assume that the borders of the maze are all walls. The start and destination coordinates are represented by row and column indexes.
Example 1:
1 | |
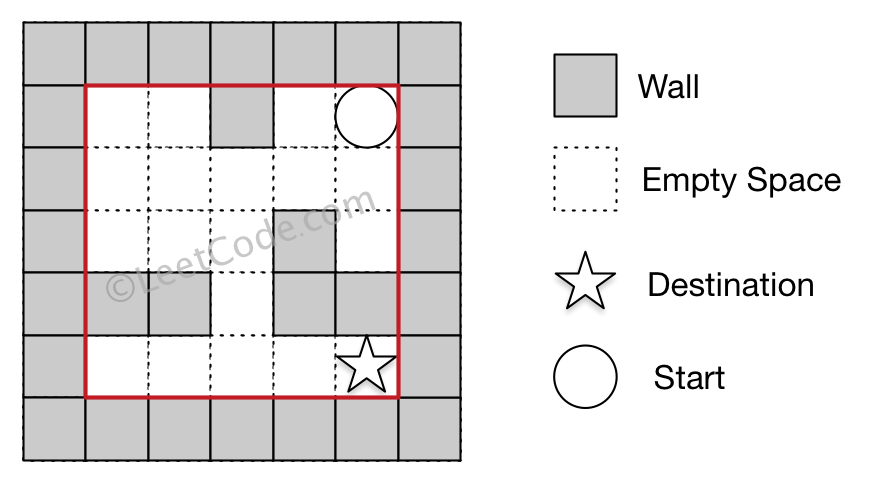
Example 2:
1 | |
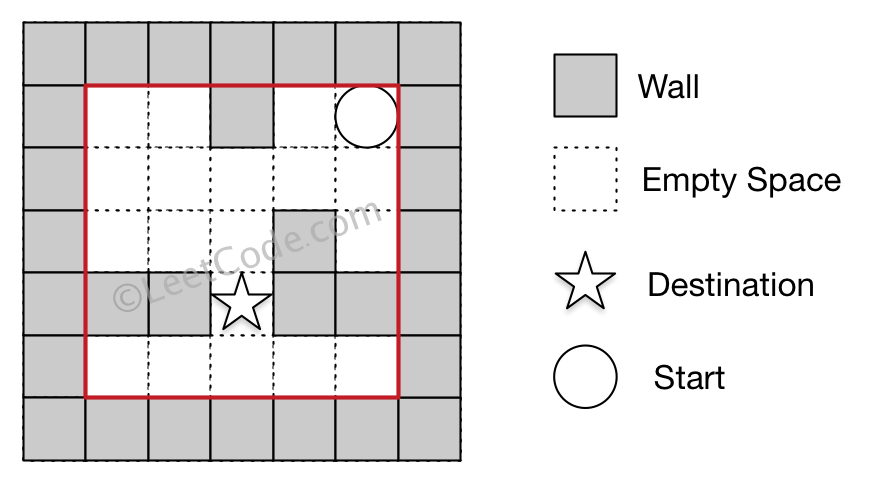
Note:
-
There is only one ball and one destination in the maze.
-
Both the ball and the destination exist on an empty space, and they will not be at the same position initially.
-
The given maze does not contain border (like the red rectangle in the example pictures), but you could assume the border of the maze are all walls.
-
The maze contains at least 2 empty spaces, and both the width and height of the maze won’t exceed 100.
Explanation 1
-
We can use DFS to solve this problem.
-
While the ball is not outside the boundary and not hitting the wall, we keep updating the ball’s position toward the current direction. When the ball stops, we recursively call the helper function.
-
We can mark the visited position as -1 in the
mazearray to avoid duplication.
Solution 1
1 | |
Explanation 2
-
We can also use BFS to solve this problem.
-
We put the ball’s start position into the queue. While queue is not empty, we pop the ball’s starting position out. First check if this position is the destination position, then updating the ball’s position until it hits the wall or outside boundary. Then pass the ball’s stopping position into the queue. Repeat until queue is empty.
Solution 2
1 | |
Random Point in Non-overlapping Rectangles
Given a list of non-overlapping axis-aligned rectangles rects, write a function pick which randomly and uniformily picks an integer point in the space covered by the rectangles.
Note:
-
An integer point is a point that has integer coordinates.
-
A point on the perimeter of a rectangle is included in the space covered by the rectangles.
-
ith rectangle =rects[i]=[x1,y1,x2,y2], where[x1, y1]are the integer coordinates of the bottom-left corner, and[x2, y2]are the integer coordinates of the top-right corner. -
length and width of each rectangle does not exceed
2000. -
1 <= rects.length <= 100 -
pickreturn a point as an array of integer coordinates[p_x, p_y] -
pickis called at most10000times.
Example 1:
1 | |
Example 2:
1 | |
Explanation of Input Syntax:
The input is two lists: the subroutines called and their arguments. Solution’s constructor has one argument, the array of rectangles rects. pick has no arguments. Arguments are always wrapped with a list, even if there aren’t any.
Explanation
-
We can use Reservoir Sampling to solve this problem. In the constructor, we can just pass the
rects[][]to the class fieldthis.rects. In thepick()method, in order to use reservoir sampling, we need to have a variablesumAreawhich means the sum of all rectangles’ area. When iterate all the rectangles, we first updatesumArea. Then the current rectangle’s area will be the pool size. If the random area between 1 tosumAreainclusive is less than or equals to the current rectangle’s area, then we will choose this rectangle to find random point. -
After iterating all rectangles and getting the selected rectangle, we can random pick any point on this selected rectangle.
-
To calculate area, we will add 1 to rectangle’s width and add 1 to its height since the point can on the corners. For example, if we have rectangle
[0, 0, 1, 1], the normal area will just be 1. but since points can on corner, we have 4 points[0,0], [0, 1], [1, 0], [1, 1]. we can calculate it by(1-0+1) * (1-0+1) = 4. -
Instead of randomly pick the index of the list of rectangles, we randomly pick by area because if the larger rectangle have higher chance to get picked.
Solution
1 | |
Stream of Characters
Implement the StreamChecker class as follows:
-
StreamChecker(words): Constructor, init the data structure with the given words. -
query(letter): returns true if and only if for somek >= 1, the lastkcharacters queried (in order from oldest to newest, including this letter just queried) spell one of the words in the given list.
Example:
1 | |
Note:
-
1 <= words.length <= 2000 -
1 <= words[i].length <= 2000 -
Words will only consist of lowercase English letters.
-
Queries will only consist of lowercase English letters.
-
The number of queries is at most 40000.
Hint 1:
Put the words into a trie, and manage a set of pointers within that trie.
Explanation
-
After reading the problem, first thing come up is to use Trie. From the problem’s example, we notice that when we run the
querymethod for input characterletter, ifletteris not the last character of word, we return false immediately. -
For example, after we query letter
d, it’s the end of one of the word, then we query its previous letterc, and we find outcdis a word, so we return true. -
We can modify the Trie a little bit, instead of inserting each word, we insert the reverse of each word. So the trie will have
["dc", "f", "lk"]. Also, when we query, we need to keep the previous letters. For example, we queryd, it’s in the trie, then we queryc. So each time when we query a letter, we append this character in the beginning of a list, so we can use a deque for this list. After we insert the letter into the deque, for example, when we are on letterd, we have[d, c, b, a]. We pass this deque to the Trie’s search method to search if the character is end of word.
Solution
1 | |
Sum of Left Leaves
Find the sum of all left leaves in a given binary tree.
Example:
1 | |
Explanation
-
We can use recursion to solve this problem. We create a helper method that will return an interger.
-
The base case will be if the TreeNode is null, then we return 0.
-
So, if it has left or right child, that means this TreeNode is not a leave, we cannot add its value. So, we recursivly check its left and right child. For its left child, we should have a boolean variable that denotes it’s left child. In the left child’s helper recursive function,
isLeftshould be true. In the right child’s helper recrusive function,isLeftshould be false. We add both recusive function’s return result tores. At the end, we returnres.
Solution
1 | |
Minimum Cost For Tickets
In a country popular for train travel, you have planned some train travelling one year in advance. The days of the year that you will travel is given as an array days. Each day is an integer from 1 to 365.
Train tickets are sold in 3 different ways:
a 1-day pass is sold for costs[0] dollars;
a 7-day pass is sold for costs[1] dollars;
a 30-day pass is sold for costs[2] dollars.
The passes allow that many days of consecutive travel. For example, if we get a 7-day pass on day 2, then we can travel for 7 days: day 2, 3, 4, 5, 6, 7, and 8.
Return the minimum number of dollars you need to travel every day in the given list of days.
Example 1:
1 | |
Example 2:
1 | |
Note:
-
1 <= days.length <= 365 -
1 <= days[i] <= 365 -
daysis in strictly increasing order. -
costs.length == 3 -
1 <= costs[i] <= 1000
Explanation 1
-
We can use dynamic programming to solve this problem.
-
Dynamic state is
dp[i]represents the minimum cost fordays[i]todays[days.length-1]. -
Dynamic init is
dp[dp.length-1]is the minimum betweencosts[0], costs[1], costs[2]. -
Dynamic function. For
ifrom right to left, start from the second last day, in other word,dp[dp.length-2]is either choose to buy a 1-day ticket, 7-day ticket, or 30-day ticket. If buying a 1-day ticket, then the cost will becosts[0] + dp[i + 1]. If buying a 7-day ticket, then the cost will becosts[1] + dp[j]wheredays[j] >= days[i] + 7.Similarlly, if buying a 30-day ticket, then the cost will becosts[2] + dp[k]wheredays[k] >= days[i] + 30. -
For example,
days = [1,4,6,7,8,20]. Wheniis the last index pointing to day 20, the cost will be the minimum prices among these 3 tickets. Wheniis the second last index points to day 8, buying 1-day ticket cost will becosts[0] + dp[i + 1]. Buying 7-day ticket will cover day 8 to day 14 inclusive, but day 20 is not cover, so the total cost will becosts[1] + dp[i + 1]. Buying a 30-day ticket will cover day 8 to day 37 inclusive, so the total cost will becosts[2]. After we calculate all 3 options, we take the minimum as the result fordp[i]. -
Dynamic result is
dp[0].
Solution 1
1 | |
Explanation 2
- We can also use top down approach.
Solution 2
1 | |
Fizz Buzz
Write a program that outputs the string representation of numbers from 1 to n.
But for multiples of three it should output “Fizz” instead of the number and for the multiples of five output “Buzz”. For numbers which are multiples of both three and five output “FizzBuzz”.
Example:
1 | |
Explanation
- Loop from 1 to
ninclusive. Check every conditions using module operator, and add each condition result to the result list.
Solution
1 | |
Find Right Interval
Given a set of intervals, for each of the interval i, check if there exists an interval j whose start point is bigger than or equal to the end point of the interval i, which can be called that j is on the “right” of i.
For any interval i, you need to store the minimum interval j’s index, which means that the interval j has the minimum start point to build the “right” relationship for interval i. If the interval j doesn’t exist, store -1 for the interval i. Finally, you need output the stored value of each interval as an array.
Note:
-
You may assume the interval’s end point is always bigger than its start point.
-
You may assume none of these intervals have the same start point.
Example 1:
1 | |
Example 2:
1 | |
Example 3:
1 | |
NOTE: input types have been changed on April 15, 2019. Please reset to default code definition to get new method signature.
Explanation
-
It’s trivial to use brute force to solve this problem in $O(n^2)$ time. We can do better in $O(n log n)$ time by sorting the intervals base on start time, then loop through the original input
intervals, make each iteration’s interval end time astarget, then use binary search to find the smallest start time that is equal or greater thantarget. -
Since we need to return its index, we can make a list of pair, each pair is the start time and its corresponding index. For example,
[[startTime, idx], [startTime, idx], [startTime, idx]], and we sort this list by startTime. After we find the smallest startTime that is equal or greater thantarget, we return its corresponding index.
Solution
1 | |
Implement Rand10() Using Rand7()
Given a function rand7 which generates a uniform random integer in the range 1 to 7, write a function rand10 which generates a uniform random integer in the range 1 to 10.
Do NOT use system’s Math.random().
Example 1:
1 | |
Example 2:
1 | |
Example 3:
1 | |
Note:
-
rand7is predefined. -
Each testcase has one argument:
n, the number of times thatrand10is called.
Follow up:
-
What is the expected value for the number of calls to
rand7()function? -
Could you minimize the number of calls to
rand7()?
Explanation
-
First we run
rand7()and store inv1, runrand7()and store inv2. -
v1only stores number from 1 to 5 inclusive, whilev1is greater than 5, we runrand7()again. -
v2only stores number from 1 to 6 inclusive, whilev2is equal to 7, we runrand7()again. -
Now for
v2, the probability of getting 1 to 3 is equal to getting 4 to 6. Ifv2is between 1 to 3, we can returnv1immediately. Else if it’s in between 4 to 6, then we returnv1 + 5.
Solution
1 | |
Week 5: August 29th - August 31st
Robot Room Cleaner
Given a robot cleaner in a room modeled as a grid.
Each cell in the grid can be empty or blocked.
The robot cleaner with 4 given APIs can move forward, turn left or turn right. Each turn it made is 90 degrees.
When it tries to move into a blocked cell, its bumper sensor detects the obstacle and it stays on the current cell.
Design an algorithm to clean the entire room using only the 4 given APIs shown below.
1 | |
Example:
1 | |
Notes:
-
The input is only given to initialize the room and the robot’s position internally. You must solve this problem “blindfolded”. In other words, you must control the robot using only the mentioned 4 APIs, without knowing the room layout and the initial robot’s position.
-
The robot’s initial position will always be in an accessible cell.
-
The initial direction of the robot will be facing up.
-
All accessible cells are connected, which means the all cells marked as 1 will be accessible by the robot.
-
Assume all four edges of the grid are all surrounded by wall.
Explanation
-
We can use DFS to solve this problem. First, we define 4 directions in clock-wise.
dirArr = {{0, 1}, {1, 0}, {0, -1}, {-1, 0}}which represents top, right, bottom, left. Also, we create avisitedhash set to record the visited coordinates. -
In the main function, we start the DFS with the current position initialize it’s
x=0, y=0, and also the robot’s directiondir, initializediris top (0). It’s very important that we need thisdirbecause the robot needs to have a direction, then it can move accordingly. For example, if the robot is facing the right direction, then we cannot move it top or down or left. Inside the dfs helper function, first, we run thecleanfunction and add this coordinate into the hashset. -
Next, loop
iin 4 directions. Inside the loop, first, we need to update the robot’s new directionnewDir, which can bedir + i. Then we update the new x coordinate and new y coordinate base on this new direction. In other words,newX = x + dirArr[newDir][0]andnewY = y + dirArr[newDir][1]. To avoid out of boundnewDirneed to module 4. -
Next, we check this new coordinate is visited or not, if it’s not visited and
movereturns true, then we can recursively call this dfs helper function. After moving the robot to another coordinate, we need to backtrack the robot to its previous direction and previous coordinate. For example, in the below’s diagram, if the robot original at position A and original direction is top, then we move it top to position B. Then we want to backtrack to position A and face top direction. At position B, we canturnRighttwo times and move to A (at A face down direction), thenturnLefttwo times to face top direction. -
After the if check, we are in the original position and direction, that means we finish checking this position with this direction, so we change the robot’s direction and ready for the next iteration.
Solution
1 | |
Pancake Sorting
Given an array of integers A, We need to sort the array performing a series of pancake flips.
In one pancake flip we do the following steps:
-
Choose an integer
kwhere0 <= k < A.length. -
Reverse the sub-array
A[0...k].
For example, if A = [3,2,1,4] and we performed a pancake flip choosing k = 2, we reverse the sub-array [3,2,1], so A = [1,2,3,4] after the pancake flip at k = 2.
Return an array of the k-values of the pancake flips that should be performed in order to sort A. Any valid answer that sorts the array within 10 * A.length flips will be judged as correct.
Example 1:
1 | |
Example 2:
1 | |
Constraints:
-
1 <= A.length <= 100 -
1 <= A[i] <= A.length -
All integers in
Aare unique (i.e.Ais a permutation of the integers from1toA.length).
Explanation
-
The constraint of
kis actually1 <= k <= A.length. Whenk = 4, we flip the first 4 numbers from index 0 to index 3 inclusive. -
We can fist find the correct number for the last index, then find the correct number for the second last index, etc. For example, if the input array is
[3, 2, 4, 1]. We want to find the correct number for the last index (index 3), since the correct number is 4, we look fortarget = 4in the input array. After we find thetarget’s index, which is 2, then we try to maketargetat index 0 by flipping from index 0 to index 2 inclusive and we get[4, 2, 3, 1]. Now,targetis at index 0, we can flip from index 0 to index 3, and we get[1, 3, 2, 4]. Now, index 3 has the correct number. Next, we want to find the second last index (index 2)’s correct number using the same method. Repeat until we finish finding last n-1 numbers, then we have the sorted array.
Solution
1 | |
Largest Component Size by Common Factor
Given a non-empty array of unique positive integers A, consider the following graph:
-
There are
A.lengthnodes, labelledA[0]toA[A.length - 1]; -
There is an edge between
A[i]andA[j]if and only ifA[i]andA[j]share a common factor greater than 1.
Return the size of the largest connected component in the graph.
Example 1:
1 | |

Example 2:
1 | |

Example 3:
1 | |
Note:
-
1 <= A.length <= 20000 -
1 <= A[i] <= 100000
Explanation
-
We can use Union Find alogrithm to solve this problem.
-
First, loop through the input array. For each number
num, we want to union all its factors which is greater than 1 into one group. We can loop divisordfrom 2 to square root ofnuminclusive, ifnum % d == 0, then it meansdis a factor. We can groupdandnum, and also groupnum/dandnum. -
After we grouping all numbers with common factor, then we loop the input array. Each iteration, we find the current number’s parent. Then use a hashmap to record parent as key, count of element that has this parent as value. Also, each time, we record the maximum count. At the end, we return this maximum count.
Solution
1 | |
Delete Node in a BST
Given a root node reference of a BST and a key, delete the node with the given key in the BST. Return the root node reference (possibly updated) of the BST.
Basically, the deletion can be divided into two stages:
-
Search for a node to remove.
-
If the node is found, delete the node.
Note: Time complexity should be O(height of tree).
Example:
1 | |
Explanation 1
-
Besides the problem’s example, we have one more example and the remove key is 4 in this example.
1
2
3
4
5
6
77 / \ 4 8 / \ 2 6 \ / 3 51
2
3
4
5
6
77 / \ 5 8 / \ 2 6 \ 3 -
We can use recursive method to solve this problem. We can find the
keyvery quick using BST’s characteristic. If the current TreeNode’s value is equals tokey, then if one of this TreeNode’s child is null, then we return another child. If this TreeNode’s both children exist, then we replace this TreeNode’s value equals to its right child tree’s minium value, in other words, the most left node of the right child which is the inorder successor. After replacing, we recursivly remove the replaced value as key on the right child.
Solution 1
1 | |
Explanation 2
- Instead of finding the inorder successor two times, we can save the inorder successor’s parent. After replacing the root value as the inorder successor’s value, then we can delete the replaced value from inorder successor parent node. In other word,
inorderSuccessorParent.left = deleteNode(inorderSuccessor, root.val).
Solution 2
1 | |