The shelter-in-place order was extended to the end of May. LeetCode also published this May LeetCoding Challenge. Let’s continue this one day one go problem.
Week 1: May 1st–May 7th
First Bad Version
You are a product manager and currently leading a team to develop a new product. Unfortunately, the latest version of your product fails the quality check. Since each version is developed based on the previous version, all the versions after a bad version are also bad.
Suppose you have n versions [1, 2, ..., n] and you want to find out the first bad one, which causes all the following ones to be bad.
You are given an API bool isBadVersion(version) which will return whether version is bad. Implement a function to find the first bad version. You should minimize the number of calls to the API.
Example:
1 | |
Explanation
-
We can use binary search to find the first bad version.
-
The range is 1 to n inclusive. While
left < right, we find the mid number. If the mid number is not a bad version, then updateleft = mid + 1. Else, we updateright = mid. Outside the while loop, we check ifleftis a bad version. If it’s a bad version, we returnleft, else return-1.
Solution
1 | |
Jewels and Stones
You’re given strings J representing the types of stones that are jewels, and S representing the stones you have. Each character in S is a type of stone you have. You want to know how many of the stones you have are also jewels.
The letters in J are guaranteed distinct, and all characters in J and S are letters. Letters are case sensitive, so "a" is considered a different type of stone from "A".
Example 1:
1 | |
Example 2:
1 | |
Note:
-
SandJwill consist of letters and have length at most 50. -
The characters in
Jare distinct.
Hint 1:
For each stone, check if it is a jewel.
Explanation
- First put all the characters in
Jto a set. Then loop through all characters inS, if the current character is inside the set, we inrease the result. After finishing looping all characters inS, return the result.
Solution
1 | |
Ransom Note
Given an arbitrary ransom note string and another string containing letters from all the magazines, write a function that will return true if the ransom note can be constructed from the magazines ; otherwise, it will return false.
Each letter in the magazine string can only be used once in your ransom note.
Note:
You may assume that both strings contain only lowercase letters.
1 | |
Explanation 1
- We can solve it by putting all magazine’s characters into a HashMap. Then loop through the ransomNote characters, every iteration, we subtract the corresponding character’s frequency in the map. If the current character is not in the map, we return false; or if map’s frequency becomes negative we return false. At the end, outside of the loop, we return
true.
Solution 1
1 | |
Explanation 2
-
Another way is count the
ransomNotecharacter frequency first,cntis equal to the total characters in theransomNote, and we store the frequency in an int array that has size 26. -
Then loop through the characters in
magazine, if the current character in the integer array has frequency more than 1, then we decrease its frequency and decreasecnt. Ifcntis equal to 0, that means we have all the characters we need to generate theransomNote, so we returntrue. At the end, we returncnt == 0.
Solution 2
1 | |
Number Complement
Given a positive integer, output its complement number. The complement strategy is to flip the bits of its binary representation.
Example 1:
1 | |
Example 2:
1 | |
Note:
-
The given integer is guaranteed to fit within the range of a 32-bit signed integer.
-
You could assume no leading zero bit in the integer’s binary representation.
-
This question is the same as 1009: https://leetcode.com/problems/complement-of-base-10-integer/
Explanation 1
-
First, we need to find the left most bit that is equals to 1, then start from that bit to the lowest bit, for each bit, we can XOR the current bit with 1 to revert from 0 to 1, 1 to 0.
-
We can find the left most bit that is equals to 1 by starting from the highest bit, use AND operation to AND the input
numwith1 << 31,1 << 30,1 << 29… until the AND result is 1.
Solution 1
1 | |
Explanation 2
-
We can use the NOT operator to NOT the input number, but for the leading zero, we dont’ want to revert. We can use a mask represented by all bits equals to 1 to mask all the leading zero. For example, if the input number is
000101, then the mask will be111000. After we get the mask, we can NOT the mask, NOT the input number, then AND these two results. -
We can find the mask by first initialize the mask be the maximum integer, which means all 32 bits are 1. Then while the mask AND the input number is 1, we left shift the mask until the AND result is 0.
Solution 2
1 | |
First Unique Character in a String
Given a string, find the first non-repeating character in it and return it’s index. If it doesn’t exist, return -1.
Examples:
1 | |
Note: You may assume the string contain only lowercase letters.
Explanation
-
Create a map with character and its frequency.
-
Loop through the characters in the string, if the iterated character’s frequency is 1, return its index.
Solution
1 | |
Majority Element
Given an array of size n, find the majority element. The majority element is the element that appears more than ⌊ n/2 ⌋ times.
You may assume that the array is non-empty and the majority element always exist in the array.
Example 1:
1 | |
Example 2:
1 | |
Explanation
-
Using Moore Voting algorithm, initialize the first number be the result, count is 1. When we hit the second number, if the second number is equal to the first number, then we just increase count by 1. Else if the second number is not the same, then we decreae the count by 1. When we hit the next number, if the count is 0, then we update result to be that number and increase count by 1.
-
This method only works when the majority element has more than half number of the elements.
From: [LeetCode] 169. Majority Element
Solution
1 | |
Cousins in Binary Tree
In a binary tree, the root node is at depth 0, and children of each depth k node are at depth k+1.
Two nodes of a binary tree are cousins if they have the same depth, but have different parents.
We are given the root of a binary tree with unique values, and the values x and y of two different nodes in the tree.
Return true if and only if the nodes corresponding to the values x and y are cousins.
Example 1:
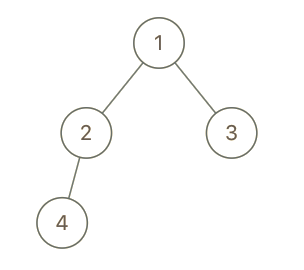
1 | |
Example 2:
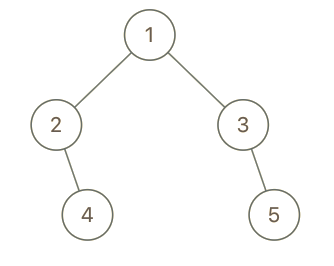
1 | |
Example 3:
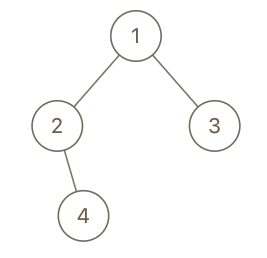
1 | |
Note:
-
The number of nodes in the tree will be between
2and100. -
Each node has a unique integer value from
1to100.
Explanation 1
-
We can use DFS to solve this problem by getting the depth of
xandyand compare their depths. Inside the same DFS function, we can also get their parents. At the end, we comparexandy’s depths if they are equal, and parents if they are not equal. -
In the main function, we create two arrays
depths[]andparents[]both have size two to recordxandy’s depths and parents. We pass these two arrays into the dfs function, as well as the current depth0and current parentnull, androot,xandy. -
In the DFS function, the base case is if the
root == NULL, then we return immediately. Ifroot.val == x, then we updatex's depthdepths[0] = curDepthandx’s parentparents[0] = curParent. Similarly for ifroot.val == y. Else, we recursively check theroot’s left child and right child, and we update thecurDepth += 1andcurParent = root.
Solution 1
1 | |
Explanation 2
-
We can also solve this problem by using BFS. First, we create a queue to store the current level’s TreeNodes and push the root node to the queue. Also, we create two variables
hasXandhasYto represent if we found the TreeNode that has valuexandy. -
While the queue is not empty, we loop through the size of the current level and each time we poll out a node
pollNode. First we check ifxandyboth have the same parent, so we check ifpollNode’s left child and right child, if their node’s value is equal toxandy, then we returnfalsebecausexandyhave the same parentpollNode. Next, we check if thepollNode’s value is equal toxory, then we markhasXorhasYbe true. After finish looping the current level, we check if bothhasXandhasYare true, if they both are true, then we returntrueimmdediately. If only one of them istruewe returnfalsebecausexandyare not in the same depth. After we checking all the nodes, or the queue is empty, we returnfalse.
Solution 2
1 | |
Explanation 3
- Another DFS solution using Go.
Solution 3
1 | |
Week 2: May 8th–May 14th
Check If It Is a Straight Line
You are given an array coordinates, coordinates[i] = [x, y], where [x, y] represents the coordinate of a point. Check if these points make a straight line in the XY plane.
Example 1:
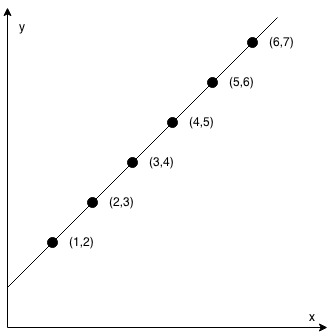
1 | |
Example 2:
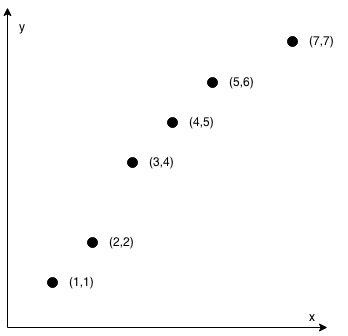
1 | |
Constraints:
-
2 <= coordinates.length <= 1000 -
coordinates[i].length == 2 -
-10^4 <= coordinates[i][0], coordinates[i][1] <= 10^4 -
coordinatescontains no duplicate point.
Hint 1:
If there’re only 2 points, return true.
Hint 2:
Check if all other points lie on the line defined by the first 2 points.
Hint 3:
Use cross product to check collinearity.
Explanation 1
-
If there are only two points, we can return true.
-
We can calculate the slope for the first two points, then loop through the input
coordinates, calculate every current point with the first point’s slope and compare this slope with the first two points’ slope. If they are not match, we can returnfalseimmediately. Outside the loop, we returntrue. -
Since the denominator cannot be 0, in the calculate slope function, we can return
-1if two points have the same x-value.
Solution 1
1 | |
Explanation 2
-
To avoid dividing by 0, we can also use cross product. For example:
1
2
3y2 - y1 y3 - y1 ------- = ------- =====> (y2 - y1) * (x3 - x1) = (x2 - x1) * (y3 - y1) x2 - x1 x3 - x1
Solution 2
1 | |
Valid Perfect Square
Given a positive integer num, write a function which returns True if num is a perfect square else False.
Note: Do not use any built-in library function such as sqrt.
Example 1:
1 | |
Example 2:
1 | |
Explanation 1
- We can use binary search to solve this problem. First we get the middle number, compare $mid*mid == num$, if they are equal, we return
true; else ifmid*mid < num, we increaseleft = mid + 1; else ifmid * mid > num, we decreaseright = mid - 1. At the end, whenleft == right, we compare the last timeleft * left == num.
Solution 1
1 | |
Explanation 2
-
For every perfect square number, we have:
1
2
3
4
5
61 = 1 4 = 1 + 3 9 = 1 + 3 + 5 16 = 1 + 3 + 5 + 7 25 = 1 + 3 + 5 + 7 + 9 36 = 1 + 3 + 5 + 7 + 9 + 11 -
From the above pattern, we can have
num -= 1,num -= 3,num -= 5, etc. Ifnum == 0Thennumis a perfect square, else we returnfalse.
Solution 2
1 | |
Find the Town Judge
In a town, there are N people labelled from 1 to N. There is a rumor that one of these people is secretly the town judge.
If the town judge exists, then:
-
The town judge trusts nobody.
-
Everybody (except for the town judge) trusts the town judge.
-
There is exactly one person that satisfies properties 1 and 2. You are given
trust, an array of pairstrust[i] = [a, b]representing that the person labelledatrusts the person labelledb.
If the town judge exists and can be identified, return the label of the town judge. Otherwise, return -1.
Example 1:
1 | |
Example 2:
1 | |
Example 3:
1 | |
Example 4:
1 | |
Example 5:
1 | |
Note:
-
1 <= N <= 1000 -
trust.length <= 10000 -
trust[i]are all different -
trust[i][0] != trust[i][1] -
1 <= trust[i][0], trust[i][1] <= N
Explanation 1
-
The town judge trust
0people, andN - 1people trust the town judge. This is like a graph problem, we need to find a vertex that its out-degree is0, its in-degree isN - 1. -
We can create two array
outDegreeandinDegreeboth have sizeN + 1, andoutDegree[i]represent the number of people theith person trust, andinDegree[i]represent the number of people trust theith person. Loop through the input array and look foroutDegree[i] == 0 && inDegree[i] == N-1, theniis the town judge.
Solution 1
1 | |
Explanation 2
- We can solve this problem by using only one array
cnt, andcnt[i]represents number of people trusti. Loop through the input array, we updatecnt[arr[0]] -= 1andcnt[arr[1]] += 1. Since there are no duplicate entries in the input array, a person can only be trusted by a maximum ofN-1people. If this person trusts anyone, then it would not be able to have value ofN-1and this is why we reduct 1 for indexarr[0]. At the end, ifcnt[i] == N - 1, theniis the town judge.
Solution 2
1 | |
Flood Fill
An image is represented by a 2-D array of integers, each integer representing the pixel value of the image (from 0 to 65535).
Given a coordinate (sr, sc) representing the starting pixel (row and column) of the flood fill, and a pixel value newColor, “flood fill” the image.
To perform a “flood fill”, consider the starting pixel, plus any pixels connected 4-directionally to the starting pixel of the same color as the starting pixel, plus any pixels connected 4-directionally to those pixels (also with the same color as the starting pixel), and so on. Replace the color of all of the aforementioned pixels with the newColor.
At the end, return the modified image.
Example 1:
1 | |
Note:
-
The length of
imageandimage[0]will be in the range[1, 50]. -
The given starting pixel will satisfy
0 <= sr < image.lengthand0 <= sc < image[0].length. -
The value of each color in
image[i][j]andnewColorwill be an integer in[0, 65535].
Hint 1:
Write a recursive function that paints the pixel if it’s the correct color, then recurses on neighboring pixels.
Explanation 1
-
Similar to [LeetCode] 200. Number of Islands, we can use DFS to solve this problem. First, we need to record the source pixel’s color as
sColor. Then fill the source pixel withnewColor, and recursively flood fill its 4 neighbors. -
The base case is if the current source is out of bound, we return; or the current source pixel’s color is not the same as
sColor, we return; or the current source pixel’s color is the same asnewColor, we return.
Solution 1
1 | |
Explanation 2
- We can also use BFS to solve this problem.
Solution 2
1 | |
Single Element in a Sorted Array
You are given a sorted array consisting of only integers where every element appears exactly twice, except for one element which appears exactly once. Find this single element that appears only once.
Example 1:
1 | |
Example 2:
1 | |
Note: Your solution should run in O(log n) time and O(1) space.
Explanation
-
Since it’s O(log n) runtime, we should use binary search to solve this problem.
-
If all elements appear twice in the array, then this array will be index0 and index1 is a pair that have the same value, index2 and index 3 is a pair that have the same value, index4 and index5 is a pair that have the same value, etc. For example
[1, 1, 2, 2]. Now, there’s one element add into the array. We have[0, 1, 1, 2, 2], or[1, 1, 2, 2, 3]. And the pair relationship is changed. -
If input is
[0, 1, 1, 2, 2], we see the middle pair[1, 2]relationship is not match, that means the added element is on the left side. If input is[1, 1, 2, 2, 3], we see the middle pair[2, 2]relationship match, that means the added element is on the right side.
Solution
1 | |
Remove K Digits
Given a non-negative integer num represented as a string, remove k digits from the number so that the new number is the smallest possible.
Note:
-
The length of num is less than 10002 and will be ≥ k.
-
The given num does not contain any leading zero.
Example 1:
1 | |
Example 2:
1 | |
Example 3:
1 | |
Explanation
-
If the number is increasing, for example,
num = 1234, then we remove from the right’sknumbers. If the number is out of order, for examplenum = 1324, andk = 1, then we should remove 3 and get124. We remove 3 because 2 is less than its left side number. -
To solve this problem, think of using a stack, iterating every number and we want to push every number to the stack, but while the stack is not empty and the current number is less than the top number on the stack, then we pop the stack. Outside of this while loop, we push the current number on the stack. For example
num = 1324, we push 1 on the stack[1], push 3 on the stack[1, 3], when current number is 2, because 2 < 3, we pop the stack and now stack is[1], we push 2 and get[1, 2], and next iteration, current number is 4, we push to stack[1, 2, 4]. What if later there are many bigger number? This doesn’t matter because those bigger numbers’ significant digit are lower than current number’s significant digit, we should lower the numbers that are in higher significant digit. -
We should consider leading zero case, if leading zero, we remove all leading zero. And when outside of the iteration, if
kis still greater than 0, we should removeknumbers from the right.
Solution
1 | |
Implement Trie (Prefix Tree)
Implement a trie with insert, search, and startsWith methods.
Example:
1 | |
Note:
-
You may assume that all inputs are consist of lowercase letters
a-z. -
All inputs are guaranteed to be non-empty strings.
Explanation 1
-
First, we need to think about what property the
Triepointer should have. Since all inputs are lowercase lettersa-z, we can create an arrayTrie[] children[26]to store the inserted characters. For example, ifchildren[0] != null, that means we have charactera. Since we need to find out if the Trie contain all characters of the word, so we need propertyboolean isEndto represent if this Trie pointer is the end of the word. -
In the constructor, we initialize
children = new Trie[26]andisEnd = false. -
In the insert method, first we need to create a pointer
curto point tothisTrie. Then loop through all characters of the word. Ifcur.children[ch - 'a']is NULL, that means we haven’t inserted this current characterchbefore, so we insert it by creating a new Trie in its corresponding index. Then update the current pointer pointing to the character’s corresponding Triecur.children[ch - 'a']. Repeat this loop. After looping all characters, we mark the current Trie’s propertyisEndto true. -
In the search method, we also need to create a pointer
curtothisTrie first. Then loop through all characters of the word, If current Trie’s children doesn’t have this current character, we return false. In other word, ifcur.children[ch - 'a']is NULL, that means we don’t have the current character in this Trie. Else, we update the pointercurto the corresponding character’s Trie. At the end, we returncur.isEndto check if this character is the end of the word. -
In the startsWith method, simillar to the search method, we loop thorugh all characters and check if the children has this character. Except outside the loop, we return true instead of
cur.isEnd.
Solution 1
1 | |
Explanation 2
- We can also use property
HashMap<Character, Trie>instead of arrayTrie[]. HashMap will save space if we have a lot of different characters.
Solution 2
1 | |
Week 3: May 15th–May 21st
Maximum Sum Circular Subarray
Given a circular array C of integers represented by A, find the maximum possible sum of a non-empty subarray of C.
Here, a circular array means the end of the array connects to the beginning of the array. (Formally, C[i] = A[i] when 0 <= i < A.length, and C[i+A.length] = C[i] when i >= 0.)
Also, a subarray may only include each element of the fixed buffer A at most once. (Formally, for a subarray C[i], C[i+1], ..., C[j], there does not exist i <= k1, k2 <= j with k1 % A.length = k2 % A.length.)
Example 1:
1 | |
Example 2:
1 | |
Example 3:
1 | |
Example 4:
1 | |
Example 5:
1 | |
Note:
-
-30000 <= A[i] <= 30000 -
1 <= A.length <= 30000
Hint 1:
For those of you who are familiar with the Kadane’s algorithm, think in terms of that. For the newbies, Kadane’s algorithm is used to finding the maximum sum subarray from a given array. This problem is a twist on that idea and it is advisable to read up on that algorithm first before starting this problem. Unless you already have a great algorithm brewing up in your mind in which case, go right ahead!
Hint 2:
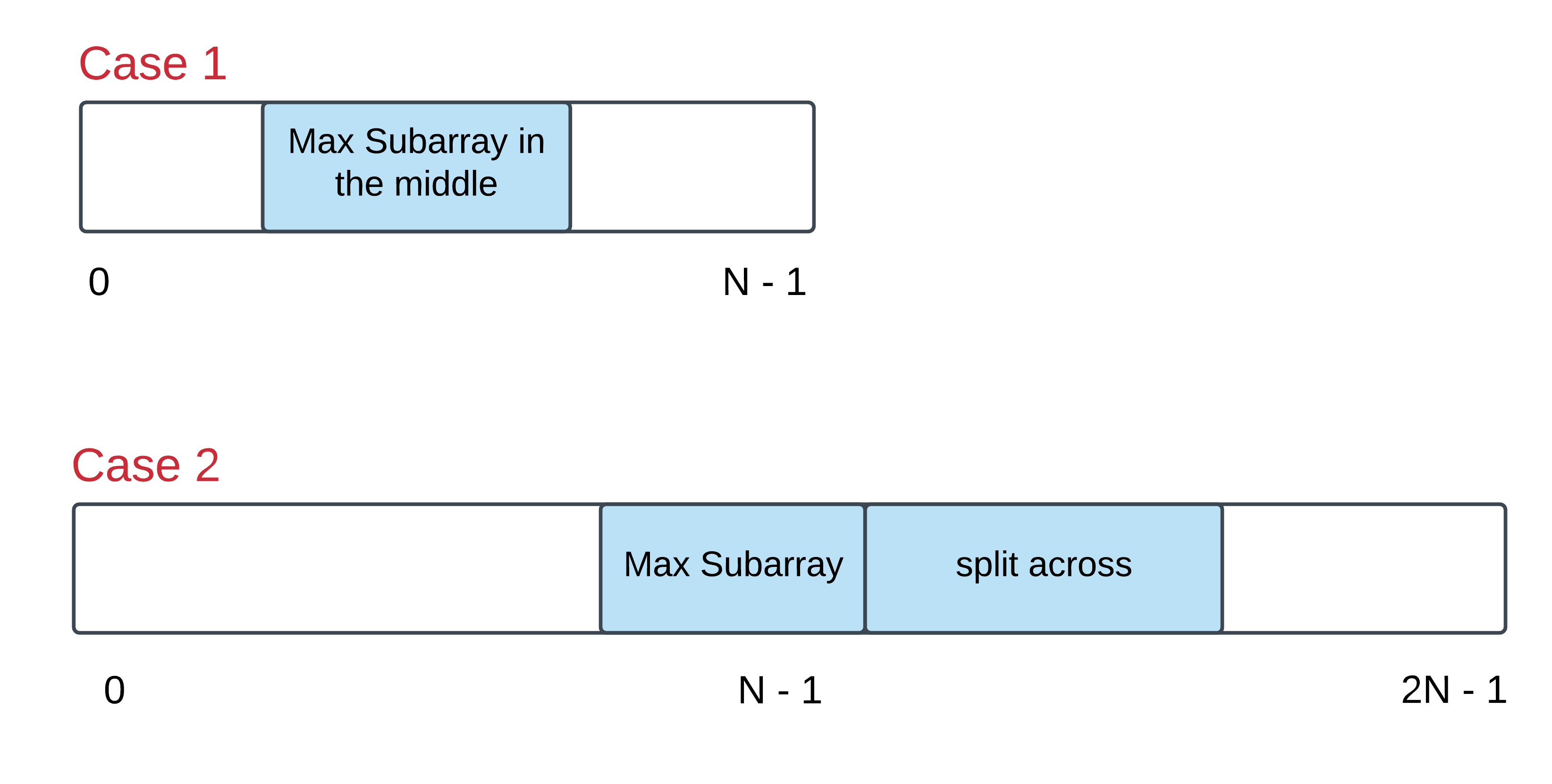
What is an alternate way of representing a circular array so that it appears to be a straight array? Essentially, there are two cases of this problem that we need to take care of. Let’s look at the figure below to understand those two cases:
Hint 3:
The first case can be handled by the good old Kadane’s algorithm. However, is there a smarter way of going about handling the second case as well?
Explanation
-
If the array is not circular, then this problem is the same as 53. Maximum Subarray, we can use Kadane’s algorithm to find out the maximum sum of the subarray. In Kadane’s algorithm, we loop through the array, for each index, we think of it as the ending index of the subarray and we calculate its maximum sum that ends at that index. For example, if the current index is
i, then the maximum sum ending at indexiismax(nums[i], nums[i] + maxSumEndAt(i-1)). -
Now in this problem, the subarray can be circular. We need to consider two cases. First case is the maximum subarray is not circular. For example,
[1, -2, 3, 4, -1, 5, -3, -1]. The maximum subarray is[3, 4, -1, 5]. We can find out the maximum sum subarray using Kadane’s algorithm. -
The second case is the maximum sum subarray is circular. For example, in
[5, -3, 1, -7, 2], the maximum sum subarray will be[2, 5]that is formed by the first number and the last number. We notice that other numbers in the middle[-3, 1, -7]is the Minimum Sum Subarray, also[2, 5] + [-3, 1, -7]is the total sum of the input array. In this case theMaxSumSubArray = totalSum - MinSumSubArray. We can actually use Kadane’s algorithm to find out theMinSumSubArray, then we use the total sum to subtract it to get the maximum sum subarray. -
After considering these two cases, we can loop through the input array, calculate the
totalSum,MaxSumSubArrayandMinSumSubArray. At the end we returnmax(MaxSumSubArray, total - MinSumSubArray). -
There’s also an edge case. If all numbers are negative in the input array, in other word, the
MaxSumSubArrayis negative, then we returnMaxSumSubArray.
Solution
1 | |
Odd Even Linked List
Given a singly linked list, group all odd nodes together followed by the even nodes. Please note here we are talking about the node number and not the value in the nodes.
You should try to do it in place. The program should run in O(1) space complexity and O(nodes) time complexity.
Example 1:
1 | |
Example 2:
1 | |
Note:
-
The relative order inside both the even and odd groups should remain as it was in the input.
-
The first node is considered odd, the second node even and so on …
Explanation
-
We can also first create an
oddpointer points to the first node,evenpointer points to the second node. Then we create aevenHeadpointer poions to the second node also. -
We make
oddpointer’s next node points ateven.next, which is always odd, thenoddpointer move one step forward. Then we makeevenpointer’s next node points atodd.nextwhich is alwasy even, thenevenpointer move one step forward. Repeat untileven.nextis NULL. -
We connect
odd.nexttoevenHead.
Solution
1 | |
Find All Anagrams in a String
Given a string s and a non-empty string p, find all the start indices of p’s anagrams in s.
Strings consists of lowercase English letters only and the length of both strings s and p will not be larger than 20,100.
The order of output does not matter.
Example 1:
1 | |
Example 2:
1 | |
Explanation 1
-
I think this solution is easier to understand. First, we add all
p’s characters in an arraypFreq[]to record the frequency ofp’s characters, and it has length 26. For example, ifpFreq[0] = 2then it meansa’s frequency is 2; ifpFreq[1] = 0then meansb’s frequency is 0. -
Initialize
startis 0, and loop through the first group orlen(p)characters ins. In each iteration, we decrease the corresponding character’s frequency by 1 inpFreq[]. For example, ifp = "abc", thenpFreq = {1, 1, 1}. If we haves = "aabc", then we check the first group’s charactersaaband subtractpFreq’s corresponding character frequency, we getpFreq = {-1, 0, 1}. -
Initialize
misMatch = false, and loop throughpFreq[]. If any frequency is not 0, that means the current group is mismatch, so we updatemisMatch = trueandbreakout this loop. After this loop, ifmisMatchis stillfalse, then we addstartto the result list. -
Now, we finish checking the first group’s character in
s, we can increasestartby 1. Now, we remove the most left characteraand update its corresponding frequency inpFreq[start - 1] += 1. Also we add the new charactercinto the current group and updatepFreq[start + len(p) - 1] -= 1. Then, we repeat the last step checking if all characters inpFreq[]have frequency 0. If true, then we updatemisMatchtofalseand addstartinto the result list. After checking, we increasestartby 1 and repeat this step whilestart <= len(s) - len(p).
Solution 1
1 | |
Explanation 2
- We can improve the last solution by counting how many miss-match characters instead of checking miss-match true of false.
Solution 2
1 | |
Permutation in String
Given two strings s1 and s2, write a function to return true if s2 contains the permutation of s1. In other words, one of the first string’s permutations is the substring of the second string.
Example 1:
1 | |
Example 2:
1 | |
Note:
-
The input strings only contain lower case letters.
-
The length of both given strings is in range [1, 10,000].
Hint 1:
Obviously, brute force will result in TLE. Think of something else.
Hint 2:
How will you check whether one string is a permutation of another string?
Hint 3:
One way is to sort the string and then compare. But, Is there a better way?
Hint 4:
If one string is a permutation of another string then they must one common metric. What is that?
Hint 5:
Both strings must have same character frequencies, if one is permutation of another. Which data structure should be used to store frequencies?
Hint 6:
What about hash table? An array of size 26?
Explanation
- In Find All Anagrams in a String, we are finding a list of starting indexes of anagrams in a string. Note, anagrams is the same as permutation. In this problem, we can use its solution to return a list of of starting indexes of permutation of
s1ins2. If this list is empty, that means there’s no permutation ofs1ins2, so we return false. Else, we return true. Or, if themisMatchCntis 0, we can return true immediately.
Solution
1 | |
Online Stock Span
Write a class StockSpanner which collects daily price quotes for some stock, and returns the span of that stock’s price for the current day.
The span of the stock’s price today is defined as the maximum number of consecutive days (starting from today and going backwards) for which the price of the stock was less than or equal to today’s price.
For example, if the price of a stock over the next 7 days were [100, 80, 60, 70, 60, 75, 85], then the stock spans would be [1, 1, 1, 2, 1, 4, 6].
Example 1:
1 | |
Note:
Calls to StockSpanner.next(int price) will have 1 <= price <= 10^5.
There will be at most 10000 calls to StockSpanner.next per test case.
There will be at most 150000 calls to StockSpanner.next across all test cases.
The total time limit for this problem has been reduced by 75% for C++, and 50% for all other languages.
Explanation 1
-
In the constructor method we create two lists
pricesandspans. In thenextmethod, we are adding a newpriceand we need to find the current price’sspan. -
We can compare current price with the its previous price, if the previous price is greater, then we add the current
priceto the listprices, and current price’s span is 1 and add to thespanslist. -
Else if the previous price is smaller, then previous price’s span will also be part of the current price’s span. From the problem’s example, if current price is 85, its previous price is 75, previous price’s span is 4, then we update the new previous price be
previousPriceIdx = previousPriceIdx - 4which now points to price 80 at index 1. Repeat this step, we compare current price 85 with the new previous price 80. Since current price is greater and previous price’s span is 1, we updatenewPreviousPrice = newPreviousPrice - 1. Now previous price is 100 which is greater than current price 85, we stop here. Now, we can calculate current price’s span is current price’s index minus previous price’s index. In this case, current price 85’s span is 6 - 0 = 6.
Solution 1
1 | |
Explanation 2
- We can also use stack of a
pair<price, span>to solve this problem. In thenextmethod, we initialize current price’sspanis 1. While current price is greater than the top stack’s price, we updatespan = span + st.top().secondand pop the stack. Outside this while loop, we add current price and the updated span to the stack, and return the updated span.
Solution 2
1 | |
Kth Smallest Element in a BST
Given a binary search tree, write a function kthSmallest to find the kth smallest element in it.
Note:
You may assume k is always valid, 1 ≤ k ≤ BST’s total elements.
Example 1:
1 | |
Example 2:
1 | |
Follow up:
What if the BST is modified (insert/delete operations) often and you need to find the kth smallest frequently? How would you optimize the kthSmallest routine?
Hint 1:
Try to utilize the property of a BST.
Hint 2:
Try in-order traversal. (Credits to @chan13)
Hint 3:
What if you could modify the BST node’s structure?
Hint 4:
The optimal runtime complexity is O(height of BST).
Explanation 1
-
We can use in-order traversal to solve this problem. In a recrusive way, we can first create a list to store all the elements that are traversaled and pass it to the recursive function. If the list has size
kor the node isnull, then we return out of the recursive function. In the main function, we can check if the list has sizek, if it does, then return thekelement in the list, else return-1. -
Instead of storing an element into a list each time, we can also increment a counter. When the counter is equal to
k, we store the element’s value into theresultvariable and return the result at the end.
Solution 1
1 | |
Explanation 2
- We want to find the
kth smallest element. First, count how many nodes in the left subtree. If there arecntnodes in the left subtree, includingroot.left, andcnt >= k. Then, we recursivly call the main method with parameter(root.left, k). Ifk > cnt+1, then thekth node is in the right subtree; we plus one because that one is the root node. Ifcntdoesn’t satisfy the above two conditions, then returnroot.valas the result.
Solution 2
1 | |
Explanation 3
-
For the follow up question, we find the kth smallest frequently, we can use the above method of comparing the counter. But it takes a lot of time if we recursivly calculate every node’s counter. So, we can change the
TreeNodedata structure to create aMyTreeNodedata structure to include acounterfor every node. So first, we need to build a tree ofMyTreeNode. -
After we build a tree of
MyTreeNodewe get themyRoot. Then, we create a helper function similar to the above solution, comparing the counter andk. In the helper function, we first check if there is aroot.left, if yes, then similar to the above solutioin. Else, check ifkis 1, ifk=1, then we return the root node, otherwise, we check the right child node with parameterroot.rightandk-1.
Solution 3
1 | |
Count Square Submatrices with All Ones
Given a m * n matrix of ones and zeros, return how many square submatrices have all ones.
Example 1:
1 | |
Example 2:
1 | |
Constraints:
-
1 <= arr.length <= 300 -
1 <= arr[0].length <= 300 -
0 <= arr[i][j] <= 1
Hint 1:
Create an additive table that counts the sum of elements of submatrix with the superior corner at (0,0).
Hint 2:
Loop over all subsquares in O(n^3) and check if the sum make the whole array to be ones, if it checks then add 1 to the answer.
Explanation
-
Similar to 221. Maximal Square, now we are finding the number of squares instead of the maximal square. We know that if the bottom right of the square is fixed, then we have if the maximum side of the square is 1, then there is 1 square; if the maximum side of the square is 2, then there are 2 squares have the same bottom right; if the maximum side of the square is 3, then there are 3 squares have the same bottom right. So we need to iterate over the matrix and sum up each square’s maximum side.
-
We can create another matrix
dpthat have the same size as the input matrix. In this new matrix, each element is used to represent the number of maximum side of the square which bottom right square is the current square. In the top row or left column, the maximum side of each square is the same asmatrix[r][c]. Else, if the current matrix square is 0, then number of maximum side square’s bottom right at this current square isdp[r][c] = 0. If the current matrix square is not 0, then we need to consider its top square’s maximum sidedp[r-1][c], its left square’s maximum sidedp[r][c-1]and its topLeft square’s maximum sidedp[r-1][c-1], and we take the minimum among these 3 squares plus 1, and the sum will be the current square’s maximum side. -
Since we only consider top, left, and topLeft, we can save sapce by creating an array
dpthat have same size as the column of the input matrix. Now current elementdp[c]’s top is equal todp[oldC], left isdp[c-1]. In order to have topLeft for the current square, in the previous iteration, we updatetopLeft = dp[prevOldC]. Also, initially,topLeft = matrix[0][0], and if current square’s column is atcol - 1, then we updatetopLeft = dp[0].
Solution
1 | |
Week 4: May 22nd–May 28th
Sort Characters By Frequency
Given a string, sort it in decreasing order based on the frequency of characters.
Example 1:
1 | |
Example 2:
1 | |
Example 3:
1 | |
Explanation 1
- First, we need to use a HashMap to count all characters’ frequency. Then, we use a PriorityQueue or List to store the HashMap’s entry pair. Then, sort it by frequency descending. Next, we iterate the sorted PriorityQueue or List and store the entry key by the number of entry value times to the result string.
Solution 1
1 | |
Explanation 2
-
We can also use bucket sort to solve this problem. First, we store the character and its frequency to a HashMap. Next, we create an array of list. Iterate the HashMap, for each entry, its frequency will be the array’s index, its key, in other words, the character will be added to the list on that index.
-
Next, we iterate the array from right to left, if the element on the current index is null, that means there’s no list, so we continue. Else, the current index has a list, then we append the list’s character the number of index times to the StringBuilder.
Solution 2
1 | |
Interval List Intersections
Given two lists of closed intervals, each list of intervals is pairwise disjoint and in sorted order.
Return the intersection of these two interval lists.
(Formally, a closed interval [a, b] (with a <= b) denotes the set of real numbers x with a <= x <= b. The intersection of two closed intervals is a set of real numbers that is either empty, or can be represented as a closed interval. For example, the intersection of [1, 3] and [2, 4] is [2, 3].)
Example 1:
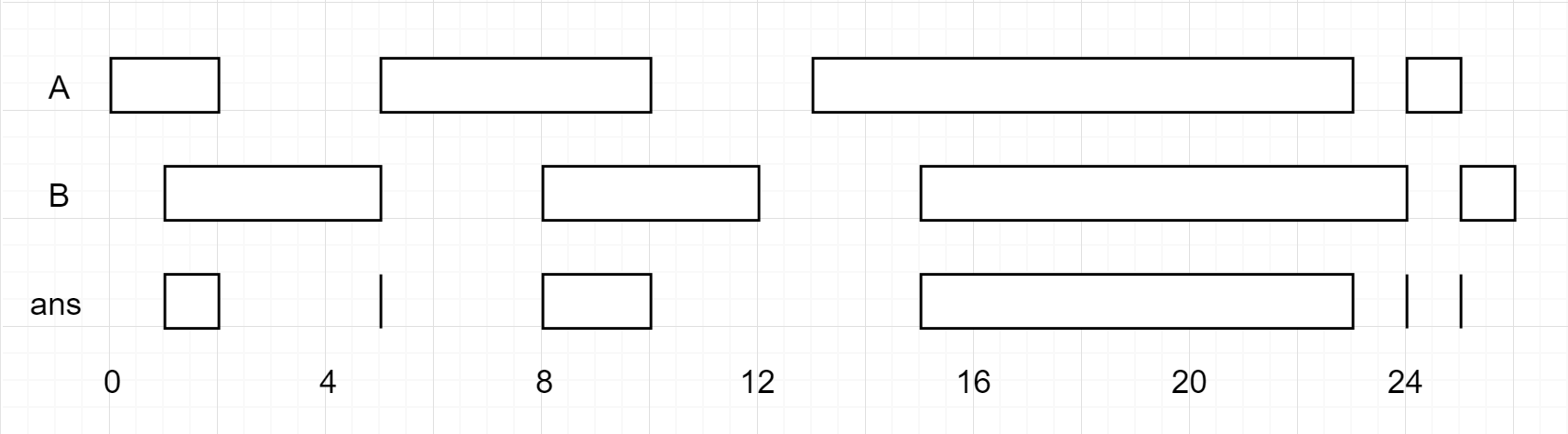
1 | |
Note:
-
0 <= A.length < 1000 -
0 <= B.length < 1000 -
0 <= A[i].start, A[i].end, B[i].start, B[i].end < 10^9
NOTE: input types have been changed on April 15, 2019. Please reset to default code definition to get new method signature.
Explanation
-
If two intervals
aandbare overlapped, we can get the intersection byintersection = {max(a[0], b[0]), min(a[1], b[1]) }. -
We use
iandjto denote the index of the current intervals ofAandBrespectively. Whilei < len(A) && j < len(B), then we keep comparingA[i]andB[j]. -
Let’s use variable
aandbto denote the current intervalA[i]andB[j]respectively. There are only two cases whenaandbare not overlapped. The first case isa[1] < b[0], the second case isb[1] < a[0]. Ifa[1] < b[0], then we increasei. Ifb[1] < a[0], then we increasej. -
If
aandbare overlapped, then we calculate their intersection and add to the result list, and increase the index of the interval that’s ending earlier. Repeat these steps until outside the while loop.
Solution
1 | |
Construct Binary Search Tree from Preorder Traversal
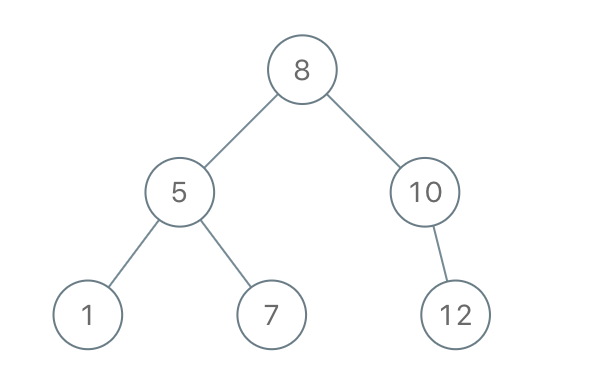
Return the root node of a binary search tree that matches the given preorder traversal.
(Recall that a binary search tree is a binary tree where for every node, any descendant of node.left has a value < node.val, and any descendant of node.right has a value > node.val. Also recall that a preorder traversal displays the value of the node first, then traverses node.left, then traverses node.right.)
Example 1:
1 | |
Constraints:
-
1 <= preorder.length <= 100 -
1 <= preorder[i] <= 10^8 -
The values of
preorderare distinct.
Explanation 1
-
Since the input array is preorder traversal, so the first element is the root. From the problem’s example,
8will be the root. How do we knowroot.leftandroot.right?root.left = 5because 5 is the next element of 8, and 5 is less than 8. To findroot.right, we need to loop from the second element to the right until the current element is greater than the root, which is10from the above example. -
Now we know
[5, 1, 7]will be in the left subtree,[10, 12]will be in the right subtree. We can create a helper method, pass the input array, and two variablesstartandendwhich represent the range of the subarray. This helper method will recursively create the binary search tree for the left subtree and right subtree.
Solution 1
1 | |
Explanation 2
-
We can also solve this problem in $O(n)$ runtime by using a global index
ito represent the current index of the input array. Reading the problem, 5 is the left child or 8, 1 is the left child of 5, …, 7 cannot be the left child of 1 since 7 > 1, and 7 cannot be the right child of 1 since 7 > 5, but 7 can be the right child of 5 since 7 < 8. -
We can create a helper method, pass in the input array and the upper bound variable
boundwhich initialize toINT_MAX. In the helper method, we create the root node,root.leftwill have the upper bound ofroot.val, androot.rightwill have the upper bound ofbound. The base case is ifi == len(preorder)orpreorder[i] > bound, then we return NULL.
Solution 2
1 | |
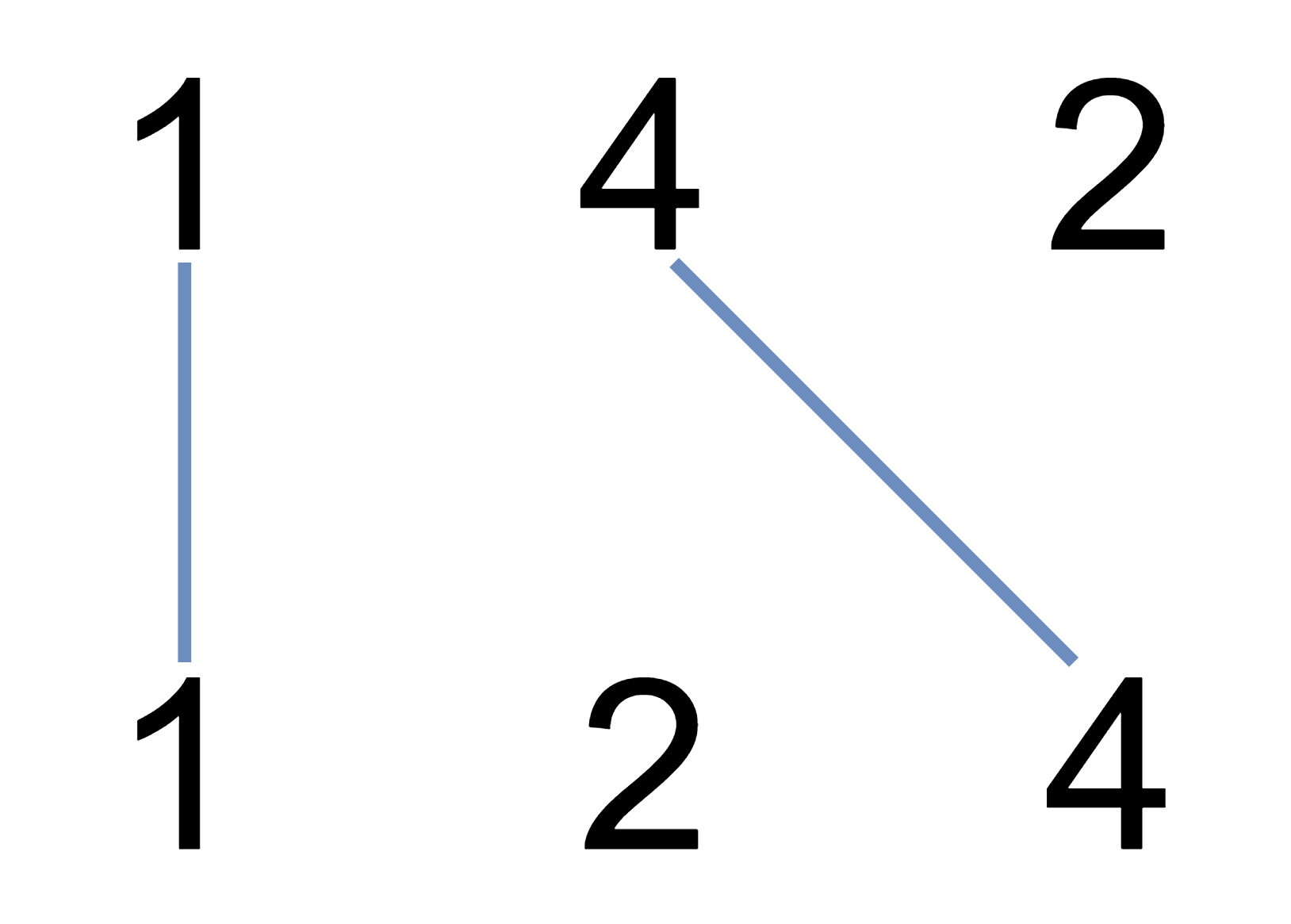
Uncrossed Lines
We write the integers of A and B (in the order they are given) on two separate horizontal lines.
Now, we may draw connecting lines: a straight line connecting two numbers A[i] and B[j] such that:
-
A[i] == B[j]; -
The line we draw does not intersect any other connecting (non-horizontal) line.
Note that a connecting lines cannot intersect even at the endpoints: each number can only belong to one connecting line.
Return the maximum number of connecting lines we can draw in this way.
Example 1:
1 | |
Example 2:
1 | |
Example 3:
1 | |
Note:
-
1 <= A.length <= 500 -
1 <= B.length <= 500 -
1 <= A[i], B[i] <= 2000
Hint 1:
Think dynamic programming. Given an oracle dp(i,j) that tells us how many lines A[i:], B[j:] [the sequence A[i], A[i+1], … and B[j], B[j+1], …] are uncrossed, can we write this as a recursion?
Explanation 1
-
This is the exact same problem as the Longest Common Subsequence (LCS) problem.
-
Dynamic init is
dp[r][c]which represents the maximum number of connecting lines we can draw forA[:r]andB[:c]inclusive. We initializedphave sizedp[len(A)+1][len(B)+1]. -
Dynamic base is if
AorBis empty, in other words, top row and left column are initialized to 0. -
Dynamic function. If the last number of both
AandBare the same, in other words,A[r-1] == B[c-1], thendp[r][c] = 1 + dp[r-1][c-1]. Else, we take the maximum ofdp[r-1][c]anddp[r][c-1]. -
Dynamic result is the bottom right number
dp[len(A)][len(B)].
Solution 1
1 | |
Explanation 2
- We can save space by using one dimensional array. Here we assume
B’s length is less thanA’s length.
Solution 2
1 | |
Contiguous Array
Given a binary array, find the maximum length of a contiguous subarray with equal number of 0 and 1.
Example 1:
1 | |
Example 2:
1 | |
Note: The length of the given binary array will not exceed 50,000.
Explanation
-
When we have any subarray problems, we can think of finding subarray’s accumulate sum to solve the problem. In this problem, if the current element is 0, we subtract 1; if the current element is 1, we plus 1. So if any subarray’s sum is 0, then this subarray will have equal number of 0 and 1.
-
We will use a hash map to record the key is the sum, the value is the current index. If next time we have the same sum, then we know in between the subarray sum to 0, and this subarray’s length will be the current index
isubtracthm.get(sum). -
Initially, we will put the entry
{0, -1}into the hashmap. For example, if the input array is[0, 1]. When we iterate to number 0, we have sum equals to -1, and we put entry{-1, 0}into the hashmap. Then when we iterate to number 1, we have sum equals to 0. We check the hashmap has key 0, so we get the length by using current index subtracthm.get(0)and we get 1 - (-1) = 2.
Solution
1 | |
Possible Bipartition
Given a set of N people (numbered 1, 2, ..., N), we would like to split everyone into two groups of any size.
Each person may dislike some other people, and they should not go into the same group.
Formally, if dislikes[i] = [a, b], it means it is not allowed to put the people numbered a and b into the same group.
Return true if and only if it is possible to split everyone into two groups in this way.
Example 1:
1 | |
Example 2:
1 | |
Example 3:
1 | |
Note:
-
1 <= N <= 2000 -
0 <= dislikes.length <= 10000 -
1 <= dislikes[i][j] <= N -
dislikes[i][0] < dislikes[i][1] -
There does not exist
i != jfor whichdislikes[i] == dislikes[j].
Explanation
-
This is a graph problem. Each pair of dislike, both numbers are connected by an edge. First, we can construct a graph using adjacent list to represent the input
dislikes. -
Each vertex can belong to one of the two groups. We can create an array
groupand initialized every value be -1, which means all vertexes are not colored.group[i]represents the color that vertexirepresents. If it belongs to group0, thengroup[i] = 0; if it belongs to group1, thengroup[i] = 1. -
We can use DFS to fill the color of every vertex. In the main function, loop through every vertex, if it doesn’t have color, then we pass the adjacent list, color array, current vertex, color 0 to the helper function and call it. If the DFS helper function returns false, then we immediately return false. After checking every vertex, we can return true.
-
Inside the helper function, if the current vertex already has color, then we compare its color with the color we pass in, if they are the same, then we return true, else return false. Else the current vertex doesn’t have color, then we fill the current vertex with the color we pass in. Next, we loop through the current vertex’s neighbor vertex, and recursively call the helper function with a color that is different from the current vertex’s color. If in any iteration, the recursive function return false, then we return false immediately. Outside the loop, we return true.
Solution
1 | |
Counting Bits
Given a non negative integer number num. For every numbers i in the range 0 ≤ i ≤ num calculate the number of 1’s in their binary representation and return them as an array.
Example 1:
1 | |
Example 2:
1 | |
Follow up:
-
It is very easy to come up with a solution with run time O(n*sizeof(integer)). But can you do it in linear time O(n) /possibly in a single pass?
-
Space complexity should be O(n).
-
Can you do it like a boss? Do it without using any builtin function like __builtin_popcount in c++ or in any other language.
Hint 1:
You should make use of what you have produced already.
Hint 2:
Divide the numbers in ranges like [2-3], [4-7], [8-15] and so on. And try to generate new range from previous.
Hint 3:
Or does the odd/even status of the number help you in calculating the number of 1s?
Explanation
-
Iterate the input array starting from 1, if the current number is an even number, then
res[i] = res[i/2]; if the current number is an odd number, thenres[i] = res[i/2]+1. -
We can write out the result for number from 0 to 15.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
200 0000 0 ------------- 1 0001 1 ------------- 2 0010 1 3 0011 2 ------------- 4 0100 1 5 0101 2 6 0110 2 7 0111 3 ------------- 8 1000 1 9 1001 2 10 1010 2 11 1011 3 12 1100 2 13 1101 3 14 1110 3 15 1111 4
Solution
1 | |
Week 5: May 29th–May 31st
Course Schedule
There are a total of numCourses courses you have to take, labeled from 0 to numCourses-1.
Some courses may have prerequisites, for example to take course 0 you have to first take course 1, which is expressed as a pair: [0,1]
Given the total number of courses and a list of prerequisite pairs, is it possible for you to finish all courses?
Example 1:
1 | |
Example 2:
1 | |
Constraints:
-
The input prerequisites is a graph represented by a list of edges, not adjacency matrices. Read more about how a graph is represented.
-
You may assume that there are no duplicate edges in the input prerequisites.
-
1 <= numCourses <= 10^5
Hint 1:
This problem is equivalent to finding if a cycle exists in a directed graph. If a cycle exists, no topological ordering exists and therefore it will be impossible to take all courses.
Hint 2:
Topological Sort via DFS - A great video tutorial (21 minutes) on Coursera explaining the basic concepts of Topological Sort.
Hint 3:
Topological sort could also be done via BFS.
Explanation 1
-
This is a graph problem. We will see the BFS method first. First, we need to make an adjancent list graph represented by a list of array. The index
isublist contains all the classes that are based on first taking prerequisites classi. Also, we make a one dimensional arrayprereq[]which count the number of classes that have to finish in order to take index classi. -
In BFS, we have a queue. First, loop through the
prereq[]array, and enqueue all the classes that have 0 prerequisites to the queue. Now, while the queue is not empty, we dequeue one classp. And check thegraphindexp’s all the classes, subtract each of these classes’s number of prerequisites by 1 in theprereqarray. If the number of prerequisites class is equal to 0, then we enqueue it to the queue. -
Now the queue is empty, that means we finish taking all the classes that have 0 prerequisites. We then loop through the
prereq[]to see if every index class have value 0. If one of the index have more than 0 prerequisite class, we returnfalsebecause we cannot take that index class since we already finish all the classes that have 0 prerequisites.
Solution 1
1 | |
Explanation 2
-
We can also use DFS to solve this problem. First, we make a directed graph as above. Also, we need to make a one dimensional array
visit[]which is used to record if the classiis visited or not. We use0as unvisit,1as visit,-1as conflict. Since we use DFS, we can think of checking the classes linearly, if these classes make a circle, then it’s conflict and we return false. -
We loop through all the classes, for each class, we think of it as a starting point and use the helper function to check it.
-
In the helper function, before we DFS into the deeper class, we mark the class in the
visitarray-1. So the base case is if the class is already mark as-1, then it means we make a circle, and we immediatly returnfalse. After checking all the classes in indexi, in other word, sublist ofgraph[i], we mark classias visit1. So the base case add one more condition, ifvisit[i]is 1, then we immediately returntruesince we confirm that base on starting point classi, all its advanced class do not make a circle.
Solution 2
1 | |
K Closest Points to Origin
We have a list of points on the plane. Find the K closest points to the origin (0, 0).
(Here, the distance between two points on a plane is the Euclidean distance.)
You may return the answer in any order. The answer is guaranteed to be unique (except for the order that it is in.)
Example 1:
1 | |
Example 2:
1 | |
Note:
-
1 <= K <= points.length <= 10000 -
-10000 < points[i][0] < 10000 -
-10000 < points[i][1] < 10000
Explanation 1
-
We can sort the input array
pointsby distance, then return the firstKpoints as a result, and this will take time $n log(n)$. -
We can also use a MaxHeap to store the fist
Kpoints first. Then iterate the rest of the points, for each iteration, we compare the current point with the MaxHeap’s top point’s distance. If the current point’s distance is smaller, then we pop the MaxHeap’s maximum point out, and insert the current point to the heap. This takes $n log(K)$ time. At the end, all the heap’s points are the first K closest points to the origin.
Solution 1
1 | |
Explanation 2
- This problem asks us to find the first K short distance points and return them without sorting, so we can use quick select method to solve this problem in $O(N)$ average time complexity.
Solution 2
1 | |
Explanation 3
- We can sort the input array
pointsby distance, then return the firstKpoints as a result, and this will take time $n log(n)$. Here is using golang’ssort.Slicefunction.
Solution 3
1 | |
Solution 4
- Here is using golang’s
sort.Sortfunction.
Solution 4
1 | |
Edit Distance
Given two words word1 and word2, find the minimum number of operations required to convert word1 to word2.
You have the following 3 operations permitted on a word:
-
Insert a character
-
Delete a character
-
Replace a character
Example 1:
1 | |
Example 2:
1 | |
Explanation 1
-
We can use dynamic programming to solve this problem. For example, word1 = “12b45”, word2 = “abcde”. We can draw a dynamic table like below.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16word2 empty a b c d e word1 +----------------------------------+ | empty | 0 1 2 3 4 5 | 1 | 1 1 2 3 | 2 | 2 2 2 3 | b | 3 3 2 3 | 4 | 4 4 3 3 | 5 | 5 + -
State is
dp[r][c], which represents the minimum operation to convertword1[0, r-1]toword2[0, c-1]. -
Init is when word1 is empty (top row), if word2 is also empty, then there are 0 operation to convert word1 to word2; if word2 has length 1, then there are 1 insert operation to convert word1 to word2; if word2 has length 2, then there are 2 insert operations to convert word1 to word2; if word3 has length 3, then we need 3 insert operations, etc.
-
When word2 is empty (left most column), if word1 is also empty, then there are we need 0 operation; if word1 has length 1, then we need 1 remove operation; if word1 has length 2, then we need 2 remove operation, etc.
-
Dynamic function is if the last character of both words are the same, for example, word1 = “12b”, word2 = “ab”, then the number of operations we need is the same as comparing word1 = “12” and word2 = “a”. In other words, if the last characters of both words are the same, then
dp[r][c] = dp[r-1][c-1]. -
If the last character of both words are not the same, for example, word1 = “12b4”, word2 = “abc”, then we need to consider three cases:
-
Delete “4” from word1, then compare word1 = “12b” and word2 = “abc”. In other word,
dp[r][c] = 1 + dp[r-1][c]. -
Replace “4” with “c”, then compare word1 = “12b” and word2 = “ab”. In other word,
dp[r][c] = 1 + dp[r-1][c-1]. -
Insert “c” at the end of word1, then compare word1 = “12b4” and word2 = “ab”. In other word,
dp[r][c] = 1 + dp[r][c-1].
-
-
If the last character of both words are not the same, we should take the minimum among these 3 operations as the result of
dp[r][c]. -
Dynamic result is
dp[len(word1)][len(word2)]which is at the bottom right.
Solution 1
1 | |
Explanation 2
- We can also save space by using a one dimensional array by comparing the
topLeft,top, andleft.
Solution 2
1 | |